|
|
|
Sommaire |
Le gestionnaire de dialogue guide les échanges avec l’utilisateur en fonction de son état actuel, et de la représentation sémantique que lui a fourni le module de compréhension en rapport avec la dernière intervention de l’utilisateur. La représentation sémantique peut être entachée d’erreurs et notamment si le processus de transcription n’a pas été fiable. Ces erreurs peuvent amener le gestionnaire de dialogue à prendre de mauvaises décisions sur le choix de la continuité à donner au dialogue. Des mesures de confiance sont généralement associées aux éléments de la représentation sémantique. Elles aident le gestionnaire à prendre une décision sur la suite à donner au dialogue : faire totalement confiance à cette représentation et continuer le dialogue ou demander une confirmation partielle, voire une répétition. Le gestionnaire de dialogue fait ce choix en vue d’assurer la satisfaction maximale de l’utilisateur.
Nous proposons dans ce chapitre une stratégie d’aide à la décision destinée au gestionnaire de dialogue. Cette stratégie va permettre de l’informer sur la qualité du processus de reconnaissance transcription/interprétation obtenu par notre stratégie de décodage présentée dans la section 5.6 afin de lui donner les moyens de prendre la décision optimale sur le choix à faire dans la gestion du dialogue.
Notre processus de reconnaissance génère une liste structurée des N-meilleures hypothèses Lnbest. Ces hypothèses correspondent aux N-meilleures interprétations trouvées dans le graphe de mots. Une interprétation est une séquence de concepts. Ce travail considère que le calcul de la probabilité qu’une interprétation soit correcte est basé sur un ensemble suffisant d’indicateurs de confiance qui peuvent utiliser de multiples sources de connaissances sur Lnbest. Dans un premier temps, il est nécessaire de vérifier la plausabilité de l’interprétation Γ1,1w.
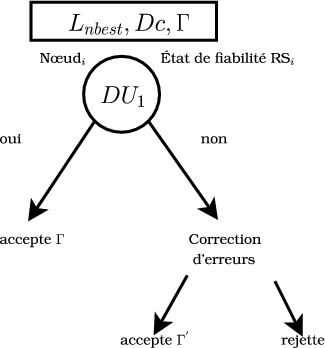
Nous proposons une stratégie d’interprétation implémentée par un arbre de décision. Au nœud j de l’arbre est appliquée une Unité de Décision DUj sur Lnbest. Les unités de décision font de la validation dans le but de mener à des états dans lesquels les erreurs de compréhension sont peu probables. Quand les résultats d’interprétation sont dans un de ces états, le gestionnaire de dialogue n’a pas à effectuer des demandes de clarification ou des demandes de répétitions. Un chemin dans l’arbre de décision stratégique défini alors un état de fiabilité de l’interprétation.
L’arbre de décision peut être automatiquement appris ou construit manuellement (comme c’est le cas dans nos expériences). Son objectif est de maximiser la couverture de cas pour lesquels l’erreur d’interprétation est en dessous d’un seuil donné. Ce seuil est choisi pour assurer la satisfaction de l’utilisateur en évitant un taux inacceptable de fausses directions dans le dialogue.
À chaque nœud de l’arbre de décision, le taux d’erreurs et la couverture sont calculées. Si une interprétation Γ est acceptée par la DU correspondant au nœud, Γ peut être traitée par une autre DU ou être transférée au gestionnaire de dialogue. Si l’interprétation est rejetée, elle peut aussi être traitée par une autre DU ou envoyée vers une unité de correction qui cherche dans Lnbest une correction Γ′ à Γ. Γ′ est alors transférée au gestionnaire de dialogue avec l’état de fiabilité attaché au dernier nœud traversé dans l’arbre, ou l’intervention de l’utilisateur est rejetée si aucune correction fiable de Γ n’est trouvée dans Lnbest. Cette stratégie est illustrée par la figure 7.1 avec une DU.
|
|
Nous présentons ici une stratégie qui s’appuie sur deux unités de décision. La première, DU1, est une unité de décision qui s’efforcera de diagnostiquer si l’interprétation Γ1,1 (séquence de concepts) supportée par l’hypothèse W1,1 produite par notre décodage est correcte. La seconde, DU2, va s’attacher à valider de manière indépendante les concepts présents dans une hypothèse. Ces deux unités de décision utilisent différents classifieurs appris sur différents paramètres pour prendre une décision.
Nous désirons mettre en place une mesure de confiance conceptuelle permettant d’estimer la qualité d’une interprétation. C’est à dire, vérifier si la séquence de concepts donnée par notre modèle est correcte. Nous avons présenté dans la section 6.5 une mesure de confiance permettant de confirmer ou d’infirmer la présence d’un concept dans une phrase. La première unité de décision DU1 va étendre cette mesure au niveau d’une interprétation.
La mesure de confiance présentée dans la section 6.5 permet de valider ou non un concept en demandant l’avis d’un classifieur entraîné à détecter sa présence selon un certain contexte. Le contexte dans ces expériences est la transcription complète. Nous interrogeons le classifieur sur tous les concepts de l’application avec la transcription complète. Il est alors possible pour chaque phrase de construire une interprétation conceptuelle associée au classifieur. Cette interprétation est la séquence de tous les concepts qui ont été détectés comme présents dans la phrase par un classifieur. Un concept est détecté présent par un classifieur, si la probabilité d’être présent donnée par le classifieur est supérieure à un seuil 1 . Ainsi nous avons 3 interprétations en plus de celle émise par notre processus de reconnaissance. Celle émise par LIA-SCT, ΓSCT, celle émise par BoosTexter, ΓBoosT, et celle émise par SVM-TORCH, ΓSV M. Ces interprétations nous donnent une idée générale de l’interprétation réelle qui existe dans la phrase. Certaines informations que renferme l’interprétation produite par notre décodage n’existent pas ici : les classifieurs ne permettent pas l’association mots/concepts, alors ces interprétations ne donnent pas d’informations sur la valeur d’un concept et la relation temporelle entre les concepts est perdue. La présence multiple d’un concept dans une phrase n’est également pas détectée.
L’interrogation des classifieurs s’appuie pour chaque intervention sur W1,1 la chaîne de mots la plus probable qui supporte Γ1,1 dans le graphe de mots. Si Γ1,1 est incorrecte parce que W1,1 contient des erreurs de reconnaissance ou des expressions qui ne sont pas générées par notre décodage mais qui supportent des concepts, alors il est probable que les classifieurs ne soient pas en accord avec notre décodage. Dans ce cas, il est possible que l’interprétation correcte doit être trouvée dans une autre candidate de Lnbest. Au contraire, si tous les classifieurs sont en accord avec l’hypothèse W1,1 générée par notre décodage, alors il est probable que l’interprétation suggérée soit correcte.
Si ΓSCT(w) est l’interprétation estimée par LIA−SCT sur l’hypothèse de mots w, ΓBOOST(w) celle donnée par BoosTexter et ΓTORCH(w) celle fournie par SV M − Torch, la situation de confiance considérée est celle représentée par l’expression logique suivante :
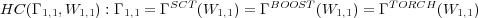
Cette unité de décision donne son avis sur la cohérence de l’interprétation fournie par notre processus de décodage en fonction de la meilleure chaîne de mots. En cas de non validation, cette unité permet également de fournir les informations suivantes :
Par contre, cette unité ne peut pas nous renseigner sur la cohérence d’une apparition multiple d’un concept.
L’unité de décision DU1 valide les concepts détectés sur W1,1. Cette unité de décision ne fournit pas d’informations sur le nombre d’occurrences d’un concept (en cas de d’apparition multiple), ni sur la valeur des concepts. Elle s’appuie sur des paramètres issus de W1,1 qui peuvent être erronés et auxquels aucune information de confiance n’est passée. C’est pourquoi les entités conceptuelles dans Γ1,1 sont validées à nouveau par une unité de décision DU2 qui se charge de valider les concepts reconnus indépendamment en tenant compte de divers paramètres de fiabilité associés.
L’unité de décision DU2 va s’efforcer de reconnaître un concept bien reconnu d’un mauvais. Cette distinction va se faire au moyen de différentes mesures de confiance. Les mesures de confiance qui peuvent être associées à un concept sont nombreuses. Certaines ont des performances globales bien meilleures que d’autres mais sont inefficaces dans certaines situations, e.g. la mesure acoustique AC qui globalement est une des plus performantes est inefficace pour estimer la confiance de concepts basés sur des mots homonymes (<Lieu:Sens> et <Prix:cent>), d’autres mesures sont alors plus pertinentes. L’idée est de combiner plusieurs mesures de confiance afin de tirer parti de leur potentiel spécifique. Cette combinaison sera faite en utilisant des classifieurs automatiques, les mêmes que ceux utilisés pour DU1, autour des indices de confiance présentés dans la section 7.3.2.
Les indicateurs de confiance suivants sont proposés :
La mesure utilisée est le CONSLM présenté dans la section 6.3.
La mesure conceptuelle présentée dans la section 6.4.2
Afin de prendre en compte le classement donné par le moteur de reconnaissance, le rang de l’hypothèse est considéré comme une mesure de confiance. Dans le cas d’une liste des N-meilleures standard, c’est le rang de l’hypothèse dans la liste. Dans le cas d’une liste structurée, le rang comporte deux nombres, le premier est le rang de l’interprétation, le deuxième est le rang de l’hypothèse pour cette interprétation.
Cette mesure est dérivée des scores de classification donnés par les différents classifieurs (section 7.2) pour une phrase de contenir un concept spécifique. Il correspond au nombre de classifieurs utilisés dans DU1 qui ont fait l’hypothèse qu’un concept était présent.
Ce contexte est représenté par le prompt du système énoncé avant l’intervention utilisateur. Chaque prompt est étiqueté avec une étiquette correspondant au type de message donné à l’utilisateur (requête spécifique, confirmation, …). Une distribution a priori de toutes les étiquettes conceptuelles pour chaque prompt est obtenue sur le corpus d’apprentissage. Pendant le décodage, la distribution attachée au prompt du système est comparée à celle détectée dans Γ1,1.
Sont également ajoutés à l’apprentissage, le nombre de mots de la phrase, le nombre de concepts reconnus, la probabilité a posteriori de la phrase, ...
Le but est de valider chaque paire concept/valeur indépendamment des autres. L’unité de décision DU2 calcule la probabilité que chaque constituant conceptuel γi (Γ1,1 = γ1,γ2,…,γi,…) est correct étant donnée une fonction de mesures de confiance pertinente, en accord avec le processus suivant :
Certains concepts ont des comportements différents : certains paramètres de confiance sont plus ou moins pertinents pour déterminer leur fiabilité. Il est alors plus judicieux, si les données d’apprentissage sont en nombre suffisant, d’entraîner un classifieur par concept. C’est ce qui a été réalisé dans nos expériences. Il est à noter que les données d’apprentissage font appel aux résultats de notre processus de reconnaissance sur le corpus de développement. Ce processus générant un liste structurée des N-meilleures hypothèses, les concepts ainsi que les mesures de confiance qui y sont attachés ne sont pas extraites que de W1,1, mais de toutes ou partie de Lnbest. Ce qui permet d’augmenter le nombre d’exemples servant à l’apprentissage des classifieurs. Dans tous les cas, il est possible d’entraîner un classifieur pour tous les concepts ou par regroupement de concepts ayant le même comportement, si les données d’apprentissage sont en nombre insuffisant pour apprendre un classifieur par concept. Les résultats de cette classification ont été obtenus en considérant les concepts extraits d’une liste structurée élaguée à l’hypothèse W3,5 et sont visibles dans le tableau 7.1. Dans ce tableau, la dernière colonne indique en choisissant le seuil optimal sur le corpus de développement le résultat de ce que l’on peut espérer de mieux de la discrimination des concepts OK ou NOK utilisant le score conceptuel acoustique AC présenté en section 6.4.2.
|
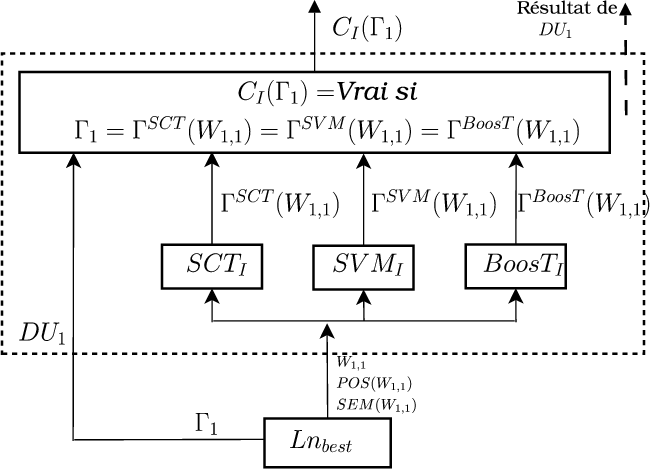
Comme dans l’unité de décision DU1, le consensus des classifieurs donne un gain de garantie sur la validité d’un concept. Une validation de consensus sur les concepts γi est une variable binaire qui est vraie si γi est étiqueté correct par tous les classifieurs V boost(γi), V tree(γi) et V SV M(γi). Ce consensus est donc l’unité de décision DU2. La fonction associée à DU2 est la suivante :
![F2[Lnbest,Dc, Γ 1,1] : ∀γi ∈ Γ 1,1,Vboost(γi) = Vtree(γi) = VSV M(γi) = correct](these_v1.0128x.png)
la figure 7.4 illustre ce procédé. L’unité de décision DU2 a été choisie pour être exécutée à la suite de l’unité DU1 dans notre arbre de décision stratégique.
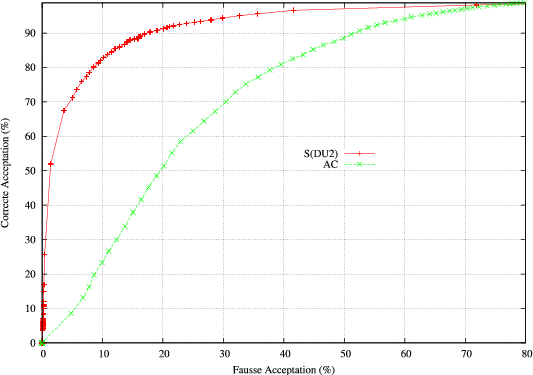
En guise d’observation, un score Sdu2 de validité de concept est calculé à partir des scores donnés par les 3 classifieurs. Ce score est comparé à la mesure de confiance AC au travers d’une courbe ROC (Receiver Operating Characteristic) dans la figure 7.3 sur le corpus de test. La courbe ROC compare, en fonction des valeurs de la mesure de confiance, les Fausses et les Correctes Acceptations d’un concept calculées de la manière suivante :
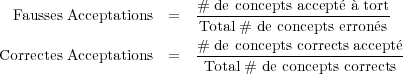
|
|
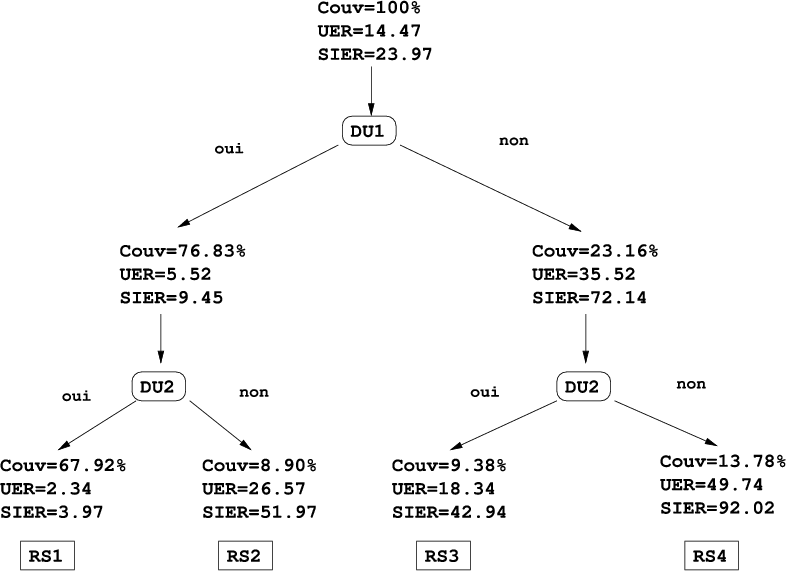
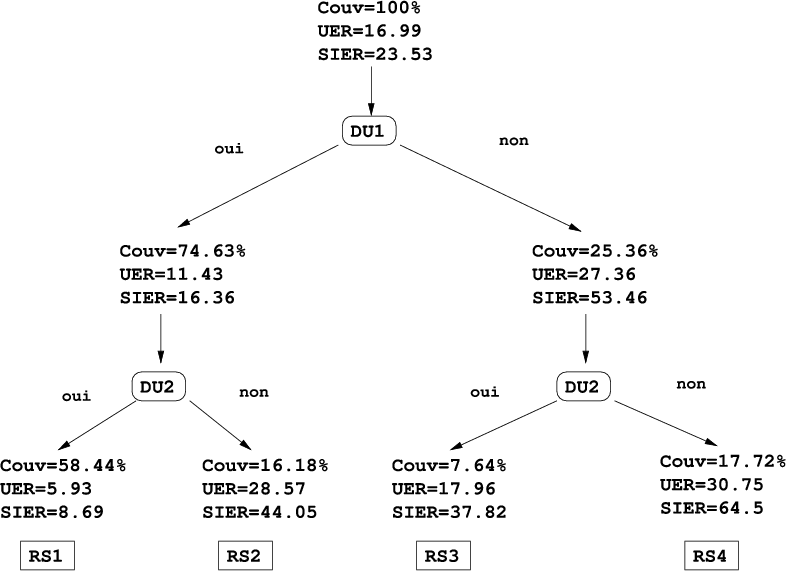
La stratégie utilisée est maintenant un arbre de décision de profondeur 2 avec en racine l’unité de
décision DU1 suivie par l’unité de décision DU2, illustrée dans la figure 7.5. Cette stratégie permet
d’isoler 4 situations de confiance :
RS1 : DU1 ∧ DU2
RS2 : DU1 ∧DU2
RS3 : DU1 ∧ DU2
RS4 : DU1 ∧DU2
RS1 correspond à la situation de validation totale, RS2 et RS3 des situations de validations intermédiaires, et RS4 une situation d’invalidation totale. Ces situations de confiance engendrées par notre stratégie sur les corpus présentés dans la section 4.2 de l’application PlanResto, sont présentées dans les arbres des figures 7.6 pour le corpus de développement et 7.7 pour le corpus de test à travers 3 mesures :
|
|
|
|
Nous pouvons effectivement remarquer que la situation de confiance optimale RS1 est un ensemble contenant des hypothèses fiables. Comme nous pouvons le voir, en validant les deux unités de décision DU1 et DU2 sur le corpus de test l’UER chute vraiment significativement de 16.99% à moins de 6%, tandis que la couverture chute seulement à 58.44%. Cette situation optimale de confiance est comparée dans le tableau 7.3 avec la situation optimale que l’on pourrait obtenir avec la mesure de confiance acoustique AC (qui est la plus performante individuellement) pour une couverture identique. Le tableau 7.2 montre l’intérêt d’appliquer le consensus de différents classifieurs dans les unités de décision en présentant le gain en fiabilité apporté par chaque classifieur.
|
|
Les 4 situations de confiance RSx présentées dans les figures 7.6 et 7.7 après applications des 2 unités de décision DU1 et DU2 peuvent logiquement être interprétées de la manière suivante :
Dans un cadre de fonctionnement plus ou moins idéal comme sur le corpus de développement, les réflexions précédentes semblent justifiées comme en atteste le tableau 7.4 qui présente les proportions de type d’erreurs commises en fonction des situations de confiance. Les expériences sur le test (tableau 7.5) montrent que ces réflexions dans une moindre mesure se confirment.
|
|
En fonction de ces considérations des stratégies de corrections d’erreurs spécifiques peuvent être mises en place. Dans tous les cas, la solution a une forte probabilité d’être présente dans Lnbest. La correction revient alors à trouver une hypothèse Γx,y ∈ Lnbest : Γx,y soit une correction pour Γ1,1. Si une hypothèse Γ1,1 est étiquetée avec un fort état de fiabilité tel RS1, il peut être hasardeux de chercher une correction dans Lnbest, sinon il est intéressant de tenter de la corriger.
Pour évaluer le potentiel de cette méthode, il est intéressant d’estimer la limite inférieure de l’UER
qui peut être trouvée dans la liste Lnbest. Cette limite est appelée taux UER Oracle. Il est obtenu à partir
de la liste d’hypothèses en sélectionnant l’hypothèse avec le plus faible UER par rapport à la référence.
Le taux UER Oracle est donné dans le tableau 7.6 pour chaque état de fiabilité RS1,2,3,4 et pour deux
types de liste d’hypothèses : une liste standard des N-meilleures hypothèses généré par un module de
RAP et la liste structurée Lnbest. Nous pouvons observer que la Lnbest surpasse significativement la
liste standard : en gardant les 10 meilleures hypothèses, l’UER Oracle est atteint pour les 4
états. Il est intéressant de noter que le taux Oracle UER est bien corrélé avec les états de
fiabilité : environ 1% pour l’état de haute fiabilité RS1 à 20% pour l’état de faible fiabilité
RS4.
|
La correction d’erreur Iq peut être vue comme un type spécial d’inférence dans laquelle une nouvelle interprétation Tq(Γi,jw) est obtenue à partir de l’interpretation Γi,jw quand un certain pre-requis Fq[Lnbest,Γi] est vrai. La forme générale du qième type de correction est :
![w w
Iq : Γi,j ∧ Fq[Lnbest,Γ i] − → Tq(Γi,j)](these_v1.0135x.png) | (7.1) |
où Fq[Lnbest,Γi] sont des expressions logiques conditionnant l’application d’une correction. Si les
corrections ne s’appliquent que sur Γ1,1w, alors : Γi,jw = Γ1,1w. Comme ces corrections sont cherchées
dans Lnbest, nous avons : Tq(Γ1,1w) = Γc,rw avec Γc,rw ∈ Lnbest.
Les types d’erreurs probables étant connus dans les situations RS2−3, il est judicieux de mettre en place des règles de correction adaptées au type d’erreurs. Des propositions de méthodes de correction sont présentées dans la section 7.5.1. Dans la situation RS4, se trouvent les hypothèses dont les erreurs sont les plus anarchiques, nous proposons une méthode de correction d’erreurs automatique dans la section 7.5.2.
Dans les situations, RS2−3, si une inconsistence sémantique est détectée dans Γ1,1 il est intéressant de tenter de la corriger. 2 types de correction sont considérés pour les situations suivantes :
Des exemples de correction de valeurs sont :
Il est utile pour établir des règles de correction d’avoir des informations liées au gestionnaire de dialogue : état du dialogue, concepts attendus, etc. Nous ne disposons pas de ces informations mais à titre d’exemple une correction possible est la suivante : sur notre corpus de développement, des inconsistances linguistiques ont été observées en utilisant une approche de type explanation based learning. Chaque exemple a été généralisé manuellement afin de construire un patron pour détecter cette inconsistance et un patron représentant la correction. Si l’inconsistance est trouvée dans Γ1,1 et la correction correspondante est trouvée dans Lnbest la correction est appliquée. Les patrons suivants ont été considérés pour corriger certaines suppressions :
Ces types de corrections sont appliqués au corpus de test dans l’état RS3 où un nombre important de suppressions est observé dans le corpus de développement. Les résultats suivants sont observés :
Si aucun de DU1 ou DU2 ne valide Γ1,1, cela veut dire que Γ1,1 est probablement au moins partiellement
incorrecte. Dans cette situation les erreurs sont plus anarchiques et il est plus difficile de trouver des
règles de correction manuelles. Nous proposons une méthode automatique pour trouver des règles de
correction.
Toutes les corrections possibles sont considérées. Elles peuvent être exprimées comme :
Les fonctions des scores de confiance associées à Fq sont apprises au moyen d’arbres de décision avec la méthode suivante :
Après la procédure d’apprentissage, les fonctions Fins, Fsup et Fsub sont représentées par les différents chemins dans l’arbre. Chaque chemin est une expression logique composée de toutes les questions sur les mesures de confiance attachées aux nœuds traversés. Les probabilités de chaque correction P{q|Fj[Lnbest,Γ]} (avec q ∈ {ins,sup,sub}) sont estimées en accord avec la distribution des exemples du corpus de développement parmi les différentes feuilles de l’arbre.
Durant le processus de décodage, cette stratégie de correction d’erreurs est utilisée seulement dans les états de faible fiabilité (RS4) : toutes les paires (Γ1,1w,Γc,rw) de Lnbest sont appliquées à l’arbre et celle avec la plus forte probabilité d’être correcte est passée à la stratégie de dialogue. Cette stratégie peut décider de rejeter la phrase si aucune solution alternative à Γ1,1w n’est trouvée dans Lnbest avec une probabilité fiable. Le tableau 7.7 montre les résultats de cette correction d’erreur.
|
Une stratégie d’interprétation séquentielle est proposée, basée sur un arbre de décision où les nœuds sont des unités de décisions effectuant des opérations de validation. La stratégie suit la conjecture que l’hypothèse faite à partir d’une intervention utilisateur doit être interprétée avec différents types de connaissances sémantiques. Nous avons proposé deux unités de décision, une pour vérifier une interprétation (séquence de concepts) extraite d’une intervention utilisateur, une autre permettant de valider un à un les différents concepts reconnus. Ces unités utilisent le consensus exprimé par différents classifieurs appris sur différentes sources de connaissances ( i.e. mots, étiquettes morpho-syntaxiques, indices de confiance, etc.) pour donner une décision. La stratégie de validation proposée permet d’isoler des situations de confiance dans lesquelles nous pouvons prédire la qualité de la reconnaissance. Ceci est une information primordiale pour le gestionnaire de dialogue afin de guider ses choix sur la poursuite du dialogue. Dans l’état de haute fiabilité, les expériences ont montré que la probabilité d’exactitude est très haute, ce qui suggère que le gestionnaire de dialogue n’a pas à demander confirmation. Dans d’autres états, l’hypothèse est incertaine et le gestionnaire de dialogue devrait demander confirmation, voire une répétition. La prédiction de la probabilité des types d’erreurs en termes d’insertions, suppressions et substitutions est également utile pour le gestionnaire de dialogue. Nous introduisons, pour les états de moindre fiabilité, des méthodes de correction d’erreurs basées sur l’utilisation de notre liste structurée qui contient toutes les corrections possibles qui existent dans le graphe de mots. Ces méthodes exploitent cette liste à travers des règles de correction manuelles ou automatiques.