|
|
|
Sommaire |
Les expériences dans les travaux présentés dans ce document ont pu être effectuées grâce à France Télécom Recherche et Développement qui a fourni les données. Les données sont celles de deux applications de dialogue homme-machine par téléphone, AGS et PlanResto.
Le démonstrateur Audiotel Guide des Services (AGS) est une application de dialogue homme-machine par téléphone, elle est décrite dans [Sadek et al., 1996]. Le démonstrateur AGS est utilisé afin de fournir à un utilisateur humain des numéros de téléphone de serveurs vocaux spécialisés dans les prévisions météorologiques ou la recherche d’emploi. Le dialogue qui s’établit par téléphone entre le démonstrateur et l’utilisateur humain a pour but de guider l’utilisateur vers le serveur le plus pertinent vis-à-vis de sa demande de renseignements.
Les données d’apprentissage se présentent sous la forme d’un corpus de transcriptions de phrases prononcées par des utilisateurs du démonstrateur AGS. Il ne s’agit pas d’un grand corpus, puisqu’il est composé de 9842 phrases, pour 49591 mots, dont 821 différents. Ces phrases ont été récupérées à partir d’une collecte de données effectuées à l’aide de locuteurs naïfs et de locuteur experts. Les locuteurs naïfs sont des personnes externes ne travaillant pas pour France Télécom R&D et n’ayant pas de connaissances en reconnaissance de la parole. Les locuteurs experts travaillent pour France Télécom R&D. Les 821 mots du corpus d’apprentissage font partie des 880 mots du lexique du démonstrateur AGS. Plus de détails sur l’acquisition des corpora de test et d’apprentissage sont donnés dans [Damnati, 2000].
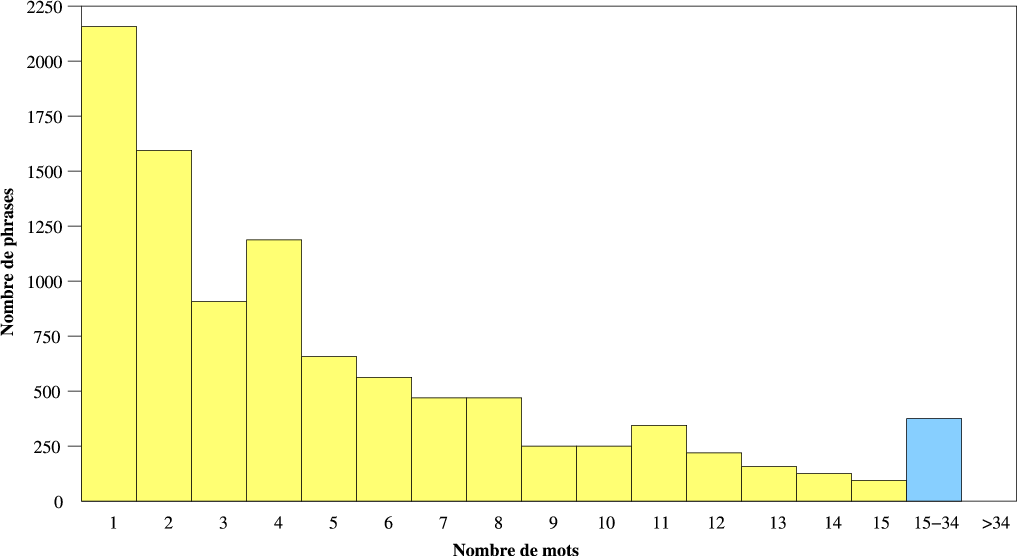
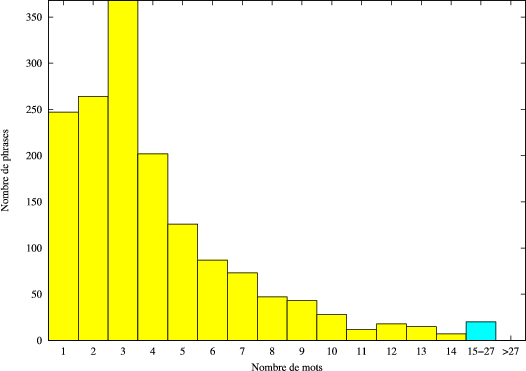
Les phrases du corpus d’apprentissage sont des questions, des requêtes, des réponses, ou des commandes (“annulation”, par exemple). Elles concernent toutes l’application AGS. Une étude plus précise de ces phrases permet de noter qu’une grande partie d’entre elles (59%) sont des phrases courtes (1 à 4 mots). La figure 4.1 montre la répartition des phrases en fonction de leur nombre de mots.
|
|
Les données de test sont des graphes de mots issus du processus de reconnaissance de la parole du démonstrateur AGS. Chacun de ces graphes de mots est associé à une phrase, appelée phrase de référence, qui correspond à la phrase effectivement prononcée par le locuteur. Les scores acoustiques associés aux mots dans un graphe sont calculés lors de la génération du graphe par le module de reconnaissance de la parole du démonstrateur AGS.
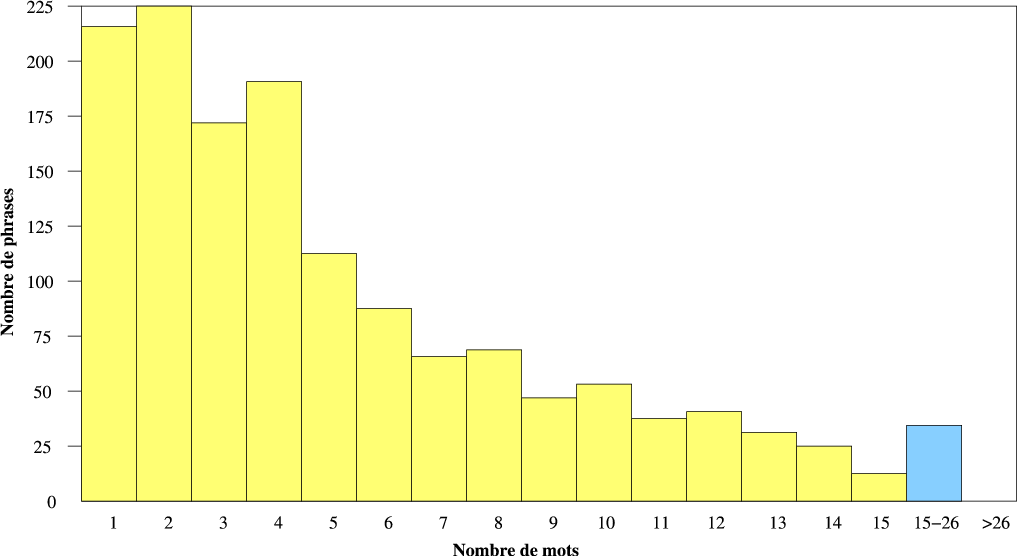
Les phrases de référence sont au nombre de 1422, composés de 7014 mots, dont 504 mots différents. La nature et la longueur de ces phrases sont semblables aux phrases du corpus d’apprentissage : la figure 4.2 illustre la répartition des phrases de référence en fonction de leur nombre de mots.
|
|
Il est intéressant de noter que sur les 504 mots différents des phrases de référence du corpus de test, 109 mots n’apparaissent pas dans le corpus d’apprentissage. Certains de ces mots n’appartiennent pas au lexique : ce sont des mots dits hors-vocabulaire. Ces 109 mots affectent 187 phrases du corpus de test, soit 13,15% des phrases de référence. Pour gérer les mots hors-vocabulaire, une entrée lexicale notée <UNK> représentant les mots inconnus est ajoutée au lexique. Au niveau de la modélisation du langage, les événements non vus sont gérés par les techniques de lissage 1 .
En dehors du problème des mots hors-vocabulaire qui affectent les performances des modèles de langage et qui a donc une incidence sur les performances globales d’un système de reconnaissance, d’autres facteurs peuvent intervenir. Le décodage acoustique, qui génère les graphes de mots, peut connaître quelques difficultés. Dans le cas du démonstrateur AGS, les conditions d’acquisition de la parole sont difficiles : utilisation du téléphone, environnements sonores différents et bruités, locuteurs différents, ... Ces conditions, associées à un lexique fermé de 880 mots, et à un élagage plus ou moins fort de l’espace de recherche, compliquent la production de graphes de mots contenant des hypothèses acoustiquement fiables. Ainsi, pour environ 24,5% des graphes, la phrase de référence n’est pas présente. Dans ce cas, il est impossible de retrouver la phrase prononcée par le locuteur à partir du graphe de mots : les hypothèses issues du processus de reconnaissance seront forcément erronées.
Les phrases du corpus de test peuvent être regroupées en fonction du locuteur qui les a prononcées. Il existe six locuteurs identifiés (l1, l2, l3, l4, l5 et l6), et un panel de locuteurs anonymes. Ce panel est nommé p0. Le tableau 4.1 montre le nombre de phrases prononcées par chaque locuteur, ainsi que le nombre de sessions de dialogue correspondantes. Une session de dialogue correspond à un appel du locuteur et à l’intégralité du dialogue associé à cet appel.
|
L’application PlanResto est une application de dialogue homme-machine par téléphone permettant à un utilisateur de rechercher un restaurant sur Paris. Il est censé fournir les mêmes services que l’application WEB PlanResto disponible à l’adresse http://paris.planresto.fr/.
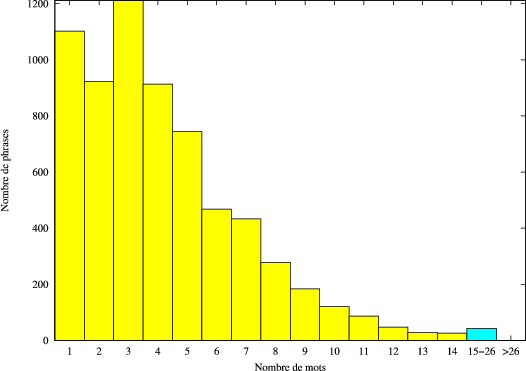
Le corpus d’apprentissage est composé de 6608 transcriptions manuelles pour un total de 27838 mots dont 1130 uniques. La figure 4.3 illustre la répartition des phrases de référence en fonction de leur nombre de mots.
|
|
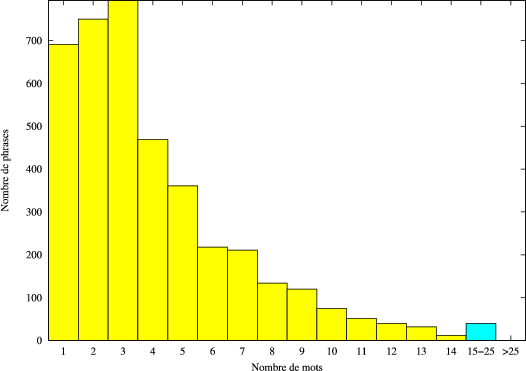
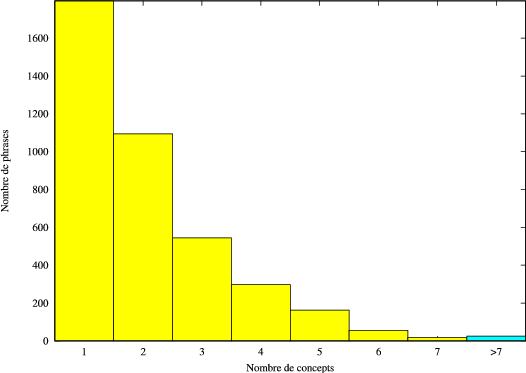
Le corpus de développement est composé de 3997 graphes de mots issus du moteur de reconnaissance de la parole (RAP) de France Telecom. À chaque graphe est associé sa référence, la phrase transcrite manuellement. Elles comportent 16239 mots dont 641 différents. La figure 4.4 illustre la répartition des phrases de référence en fonction de leur nombre de mots.
|
|
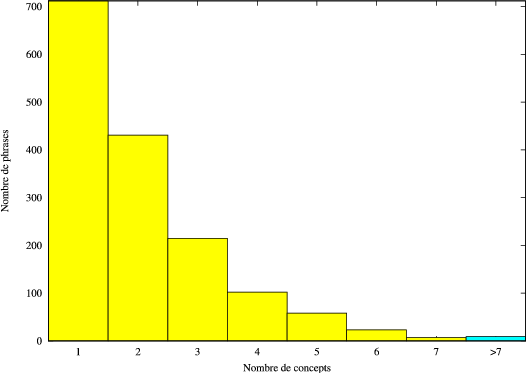
Le corpus de test est lui composé de 1557 graphes de mots issu du moteur de reconnaissance de la parole (RAP) de France Telecom. Les phrases de référence comportent 6395 mots dont 439 différents. La figure 4.5 illustre la répartition des phrases de référence en fonction de leur nombre de mots.
|
|
Les étiquettes conceptuelles représentent les unités sémantiques élémentaires extraites à partir du texte pour permettre la construction de structures sémantiques. Dans l’application PlanResto, le nombre de concepts utilisés par France Télécom est de 59 et sont listés dans la tableau 4.2.
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Les figures 4.6 et 4.7 montrent respectivement la répartition des phrases en fonction du nombre de concepts présents pour le corpus de développement et de test.
|
|
|
|
Le taux d’erreurs mot (ou Word Error Rate, WER) est une des mesures les plus utilisées pour estimer les performances d’un reconnaisseur sur la transcription produite. Un alignement est effectué entre une hypothèse de reconnaissance et la phrase de référence 2 et les erreurs sont comptabilisées et utilisées pour calculer le taux d’erreurs suivant la formule 4.1. Généralement un poids identique est accordé à chaque type d’erreur, toutefois il est possible de leur attribuer un poids différent.
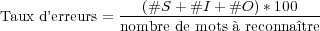 | (4.1) |
Un système peut faire trois types d’erreur. Des substitutions, notées « S », correspondent aux mots substitués à d’autres. Des omissions notées « O », c’est-à-dire des mots qui n’ont pas été trouvés par le système. Enfin, des insertions, notées « I », lorsque des mots sont insérés par erreur. Le tableau 4.3 illustre un alignement entre une référence et une hypothèse qui aura comme taux d’erreurs :
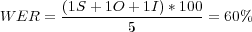
|
Dans les systèmes de dialogue, l’objectif n’est pas de transcrire sans erreurs, mais de pouvoir comprendre les sens de ce qui est prononcé. Comprendre le sens, nécessite de pouvoir détecter tous les concepts élémentaires présents dans la phrase. Ceci reste possible même avec une transcription erronée, si les erreurs de reconnaissance n’affectent pas les mots porteurs de sens. Dans ce genre d’application le taux d’erreurs mot n’est alors pas le plus pertinent. Nous utilisons alors le taux d’erreurs sur les concepts (ou Concept Error Rate, CER). Il est associé aux étiquettes conceptuelles. Par exemple pour le contexte : un restaurant à Bastille, est associé la séquence de concepts <claRestaurant> <Lieux>. La séquence de concepts reconnue est alors alignée avec la référence et le taux d’erreurs concept est calculé de manière identique au WER, en tenant compte des séquences de concepts plutôt que des mots.
Le taux d’erreurs en compréhension (ou Understanding Error Rate, UER) est associé aux valeurs normalisées des concepts détectés. À la différence du CER, les valeurs des concepts sont prises en compte (pour les concepts en possédant). Ces valeurs sont obtenues par un ensemble de règles qui transforme la séquence de mots détectée comme concept en valeur significative. Par exemple pour le contexte : un restaurant à Bastille pour cent francs est associé <claRestaurant> <Lieux:BASTILLE> <Prix:100 F>. Le UER est défini comme suit :
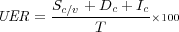 | (4.2) |
où Sc∕v indique la substitution d’un attribut de Γ ou de sa valeur, Dc indique la suppression d’un attribut Ic indique une insertion. T est le nombre total de concepts dans la référence. Un UER à 0, donne donc une reconnaissance idéale même si son taux d’erreurs mot est supérieur à 0.