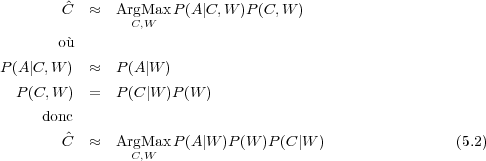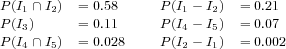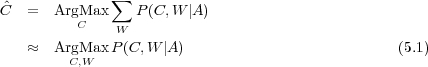
|
Sommaire |
Dans ce chapitre, nous présentons une architecture de décodage intégrant des informations conceptuelles en plus des informations acoustico-linguistiques utilisées habituellement. Ces informations conceptuelles sont représentées par des paires attribut/valeur et sont les éléments à partir desquels le module de compréhension va pouvoir construire une représentation sémantique de ce que l’utilisateur a dit. Un concept est représenté par un mot ou une séquence de mots ayant un sens pour l’application de dialogue. Nous présentons un modèle de language permettant de faire la correspondance entre ces mots et le ou les concepts qu’ils représentent. Ceci peut être vu comme une opération de traduction des mots vers les concepts.
Nous utilisons une grammaire régulière locale spécialisée pour détecter chaque concept de l’application et nous la codons sous forme de transducteur à états fini qui émet une étiquette correspondante au concept détecté. Ces transducteurs sont regroupés dans un super-transducteur qui correspond à notre modèle conceptuel capable d’analyser toute phrase et de produire la ou les interprétations conceptuelles (ensemble de concepts) associées.
L’espace de recherche de départ est la sortie d’un moteur de reconnaissance sous la forme d’un graphe de mots. Chaque chemin du graphe est une hypothèse faite par le système de RAP pour la transcription du signal de parole. Chaque transition dans ce graphe est un mot, et le score associé à chaque mot est le score combiné des scores donnés par le modèle acoustique et le modèle de langage.
En représentant le graphe de mots comme un automate à états fini et en le composant avec notre modèle, nous obtenons un espace de recherche enrichi sous la forme d’un transducteur avec comme entrée les mots et comme sortie des étiquettes conceptuelles. En ne considérant que les sorties de ce transducteur nous obtenons le graphe de concepts associé au graphe de mots. Nous présentons alors une recherche dans cet espace permettant de générer une liste structurée des N-meilleurs candidats en cherchant les meilleures interprétations disponibles. Cette liste fournit toutes les interprétations possibles qui existent dans le graphe de mots avec leurs meilleures phrases supports en terme de mots sans redondance du point de vue des informations conceptuelles.
Dans les applications de dialogue considérées dans ces travaux, l’opération de compréhension consiste à construire une représentation sémantique de l’énoncé utilisateur. L’instanciation d’une structure sémantique s’appuie souvent sur un ensemble de concepts élémentaires de la phrase reconnue plutôt que sur sa forme syntaxique [Ward, 1991, Hacioglu et Ward, 2001, Pieraccini et Levin, 1995, Aust et al., 1995, Jamoussi et al., 2004]. À partir de la séquence d’observations acoustiques A = a1a2…am extraite du signal, un système de compréhension de la parole cherche l’ensemble des concepts élémentaires Ĉ = c1c2...ck qui maximise la probabilité a posteriori P(C|A). Pour solutionner ce problème, il est commode de faire intervenir la séquence de mots W transportée par A :
d’après le théorème de Bayes la règle de décision (5.1) peut être re-formulée en : Dans la pratique il est possible de scinder le problème de la détection de C en 2 étapes séquentielles qui consistent à effectuer une transcription et à utiliser le résultat de cette transcription pour effectuer le décodage conceptuel. La transcription est obtenue en utilisant la règle de décision suivante :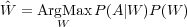
La représentation sémantique et l’extraction de concepts sont deux opérations différentes. Construire une
représentation sémantique consiste à utiliser des règles qui établissent des relations entre les concepts
détectés. La détection de concepts correspond à la mise en œuvre de règles de séquences de mots
associées à chaque entité conceptuelle. Ces règles utilisées pour détecter différents concepts dans la
même phrase peuvent utiliser les dépendances contextuelles et donc partager des mots. Ces règles sont de
taille finie car les phrases, spécialement en dialogue oral, contiennent un nombre fini et souvent petit de
mots. Le formalisme des automates à états fini est donc approprié pour modéliser ces règles.
Les précédentes considérations suggèrent de concevoir l’étape de transcription comme un processus de
décodage dans lequel les modèles de langage stochastiques (LMs) contiennent des séquences de mots
acceptées par des Machines à états fini (FSM) dont les étiquettes de sortie représentent les constituants
sémantiques, ou concepts : il y a un FSM pour chaque concept élémentaire. La définition d’un tel concept
doit satisfaire 2 contraintes majeures :
Le LM pour chaque concept peut être vu comme un langage accepté par une approximation régulière d’une grammaire représentant un langage naturel. Une telle approximation est implémentée par un transducteur à états fini dont les sorties sont des instances des concepts. Nous avons voulu que ces différents automates, représentant différents concepts, soient capables de partager des séquences de mots, sans requérir, comme dans de nombreuses approches d’analyse sémantique restreinte que les constituants sémantiques ne puissent se chevaucher [Hacioglu, 2004, Pradhan et al., 2004].
Pour satisfaire ces considérations nous proposons une architecture de décodage basée sur des connaissances à deux niveaux :
Notre approche se veut indépendante des unités conceptuelles. Leur nombre, la granularité de leur représentation est un choix qui appartient aux concepteurs d’un système. L’architecture de décodage proposée n’impose pas de restrictions. La section 5.4 présentera donc succinctement la notion de concept sans insister sur les différents choix possibles pour les représenter. Afin d’illustrer au mieux nos propos nous utiliserons des exemples en relation avec le système de dialogue oral PlanResto de France Telecom R&D (description dans le chapitre 4.2) qui est une application de serveur vocal proposant la recherche de restaurant dans Paris. La section 5.5 décrit la construction d’un modèle de langage conceptuel permettant d’enrichir un graphe de mots issu d’un module RAP avec des informations conceptuelles. La section 5.6 illustre le processus de décodage dans un nouvel espace de recherche conceptuel au travers d’un exemple simple. La sortie de ce processus permet de générer une liste structurée sémantiquement des N-meilleures hypothèses dont l’intérêt est discuté dans la section 5.7.
Afin de pourvoir interagir avec l’utilisateur, le gestionnaire de dialogue doit construire une représentation sémantique correspondant aux attentes de l’utilisateur. La construction de cette représentation sémantique, se fait au fil du dialogue grâce aux interprétations faites par le module de compréhension sur les différentes interventions de l’utilisateur. Une interprétation est l’ensemble des concepts exprimés par l’utilisateur. Dans un contexte de dialogue oral, les concepts vont correspondre aux unités sémantiques élémentaires correspondant à l’application visée. Quels que soient le module de compréhension et le gestionnaire de dialogue utilisés, ces entités doivent être détectées et reconnues afin d’obtenir les paramètres essentiels à la résolution d’une tâche par le système. L’extraction de ces entités conceptuelles (concepts) représente le premier traitement dans le processus de compréhension. Leur définition est reliée à la stratégie de dialogue. Certains concepts sont reliés à la gestion du dialogue (confirmation, contestation, …) et d’autres au domaine d’application (lieu, date, …). Un concept peut-être vu comme une paire attribut/valeur.
On peut distinguer deux types d’entités conceptuelles (voir tableau 5.1) :
|
Toutes les entités conceptuelles seront codées au final sous la forme d’un transducteur.
Les concepts avec valeurs sont détectables le plus souvent par des séquences de mots exprimées par l’utilisateur, et peuvent contenir 3 sortes de mots, des mots clefs (notés (1) dans les exemples qui suivront) qui sont indispensables car ils sont, soit caractéristiques du concept, soit ils en composent la valeur, des modifieurs (notés (2)), des mots qui informent sur la manière d’interpréter le ou les mots clefs, et des mots spécifiques (notés (3)) aux concepts dont la présence n’est pas indispensable, exemple :
Il est à noter que les modifieurs (mots de type 2) représentent une fonction sur le concept et peuvent
être communs à plusieurs concepts. Ils peuvent alors être considérés comme des concepts à part entière
(sans valeur) et être modélisés séparément. Le choix des unités conceptuelles ainsi que leur granularité
appartient au concepteur du système. Dans les exemples qui suivent, il a été choisi de les modéliser au
sein des entités dont ils sont la fonction.
L’apprentissage des règles a été effectué à partir du corpus d’apprentissage étiqueté manuellement. La
séquence de mots représentant un concept a été choisie la plus longue possible. C’est à dire que sur les 3
types de mots présentés plus haut, la séquence composée des mots clefs est suffisante pour détecter le
concept, mais nous avons voulu accepter les séquences les plus longues possibles pour deux
raisons :
Les règles apprises sur ce corpus ont ensuite été enrichies selon deux critères. Le travail de généralisation des règles de grammaires est intéressant, mais il n’est pas la priorité de ces travaux. Ce travail de généralisation a été fait de manière à ce que la couverture de nos modèles soit suffisante pour pouvoir les évaluer correctement.
Le premier critère d’enrichissement consiste à créer des classes d’équivalence entre mots qui peuvent être
interchangés dans la grammaire sans altérer sa précision. C’est notamment le cas des mots clefs :
| le troisième arrondissement | −→ | le ORDINAL arrondissement |
| type de cuisine indienne | −→ | type de cuisine SPEC |
| restaurant chinois | −→ | restaurant SPEC |
| pour moins de cent francs | −→ | pour moins de cent DEVISE |
| maximum trois cent euros | −→ | maximum UNITE cent DEVISE |
| près du métro Gaité | −→ | près du métro XLOC |
Les règles obtenues après cet enrichissement sont suffisantes pour détecter quasiment tous les concepts et permettent de surcroît de diminuer la taille et la complexité de leur représentation sous forme de transducteur. L’utilisation de classes d’équivalence telle que nous l’avons effectué fait que l’on perd certaines contraintes, comme le genre et le nombre sur les mots clefs et les mots attenants. Mais nous avons décidé de ne pas diviser ces classes en sous-classes tenant compte du genre et du nombre, car la cohérence en genre et en nombre est assurée en partie par le modèle de langage N-grammes et surtout une erreur en genre ou en nombre dans ce contexte n’a pas d’influence sur l’interprétation de la phrase.
Le deuxième critère exploite des connaissances syntaxiques du français pour déterminer des séquences de mots interchangeables au sein d’un même concept. Par exemple pour le concept de lieu les séquences suivantes sont équivalentes :

Les règles contenant une de ces séquences interchangeables sont dupliquées avec toutes les autres séquences équivalentes. Cette généralisation permet donc de pouvoir accepter le plus souvent possible les séquences de mots les plus longues.
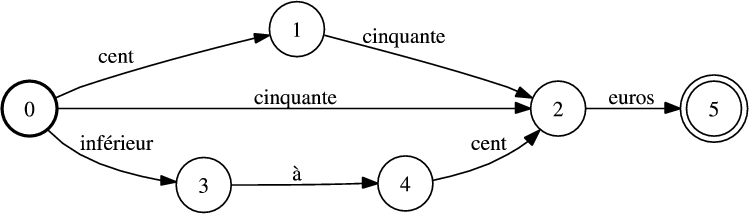
Les figures 5.1 et 5.2 illustre respectivement un exemple d’automate codant le concept de lieu et de prix.
Ces transducteurs prennent les mots en entrée et donnent en sortie les étiquettes associées aux concepts transportés par la phrase reconnue.
Nous voulons construire un modèle de langage de plus haut niveau modélisant les informations conceptuelles relatives au module de compréhension. Notre modèle conceptuel a pour objectif de représenter les différentes associations mots/concepts qui existent dans une application particulière. Ceci peut être vu comme une opération d’association ou de traduction, c’est pourquoi nous allons représenter ce modèle sous la forme d’un transducteur à états fini, ou le langage d’entrée sera composé des mots du vocabulaire (V) de l’application et le langage de sortie sera composé des concepts, identifiés par des étiquettes ou balises (B). Ce transducteur devra être capable d’analyser une phrase quelconque et émettre la ou les séquences de concepts qui peuvent y être détectés.
L’objectif du modèle conceptuel est d’enrichir le graphe de mots généré par le système de RAP avec des informations conceptuelles. Le graphe de mots G sera codé sous la forme d’un automate à états fini. Notre modèle conceptuel MC sera représenté par un transducteur à états fini. L’objectif sera d’enrichir le graphe de mots par une opération de composition entre les deux.
Les automates à états fini (ou Finite State Machine - FSM) sont un formalisme puissant, à la fois pour
représenter des structures linguistiques telles que des grammaires, mais aussi du point de vue de
l’efficacité des algorithmes permettant d’effectuer des opérations fondamentales entre eux. Le toolkit
développé à AT&T par Mehryar Mohri, Fernando Pereira et Michael Riley ([Mohri et al., 1997]), permet
de manipuler de telles structures, soit sous forme de FSM accepteur, soit sous forme de FSM
transducteur, et implémente la plupart des opérations fondamentales (voir chapitre 3.4.2) nécessaires à
leur application au traitement automatique de la langue (minimisation, déterminisation, composition,
plus court chemin, etc.).
Voir http://www.research.att.com/sw/tools/fsm/ pour plus de détails.
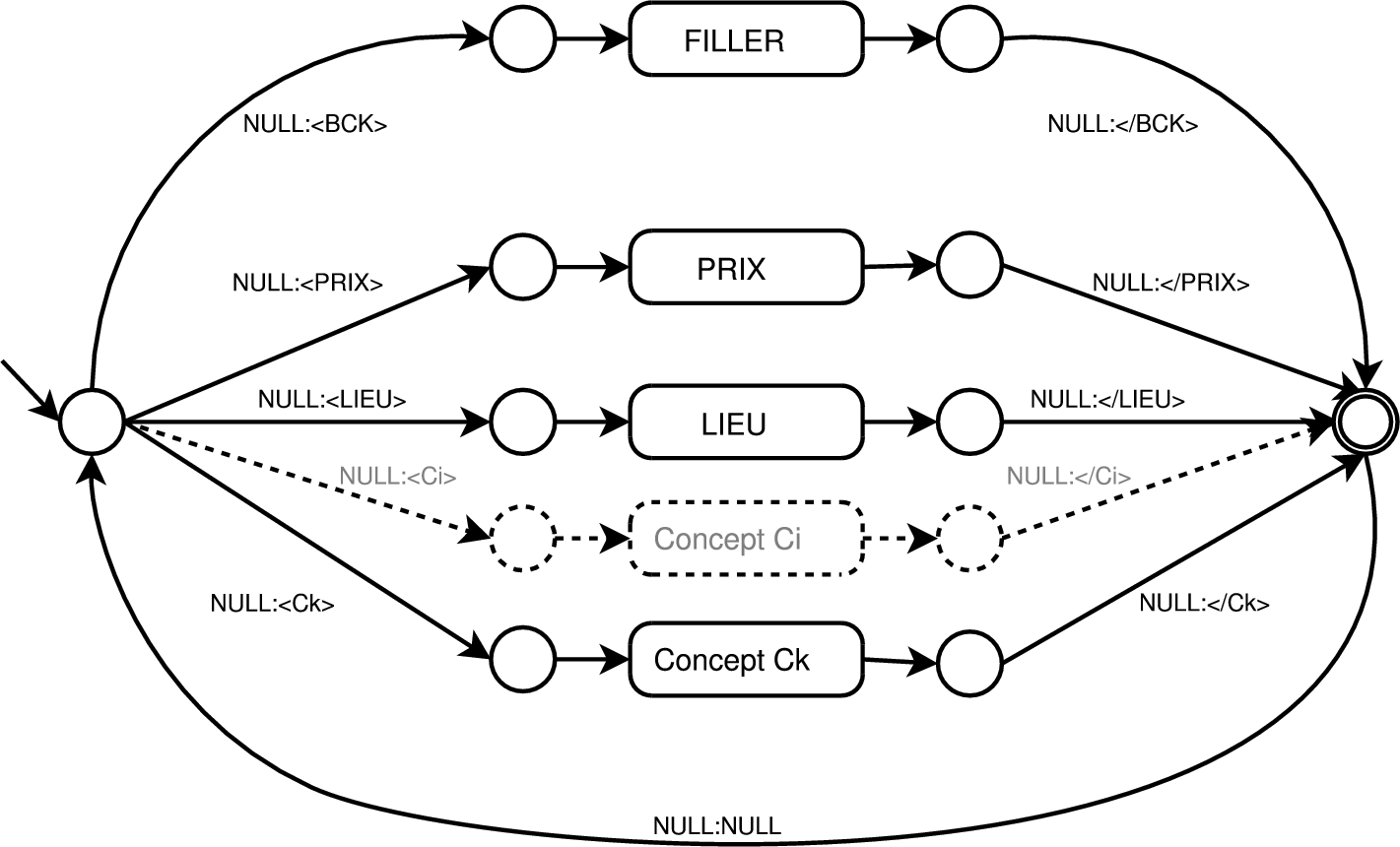
Chaque concept Ck est associé à un accepteur Ak (Ak pour le concept Ck) (exemple figure 5.1 et 5.2 pour les concepts « Lieux » et « Prix »). Dans le but de traiter les séquences de mots qui ne correspondent à aucun concept, un modèle Filler (« mange-mots ») appelé AF est utilisé (voir figure 5.3).
Chaque automate Ak est converti en transducteur Tk dont les symboles d’entrée sont les mots et les symboles de sortie sont des balises de début et fin de concept. Tous les accepteurs Ak deviennent alors des transducteurs Tk où la première transition émet le symbole <Ck> et la dernière le symbole <∕Ck>. De même, le modèle Filler devient le transducteur Tbk qui émet les symboles <BCK> et </BCK>. À l’exception de ces balises de début et fin de concept, aucun autre symbole n’est émis : tous les mots dans le Filler ou les transducteurs conceptuels émettent un symbole vide (transition 𝜖 notée « NULL » dans les différentes figures). Le modèle conceptuel, dans un premier temps, peut être vu comme un transducteur Tconcept étant l’union des transducteurs conceptuels et du transducteur Filler, où l’état final est re-bouclé sur l’état de départ afin de traiter une phrase complète, comme illustré dans la figure 5.4.
Dans cette configuration, le modèle conceptuel effectue des analyses que nous ne considérons pas optimales : pour une même chaîne de mots plusieurs analyses redondantes sont susceptibles d’être effectuées et certaines peuvent être erronées. Le but des différentes optimisations est de faire en sorte qu’en fonction d’une chaîne de mots notre modèle ne produise que des analyses non-redondantes et cohérentes.
En premier lieu, l’accepteur AF à partir duquel est construit le transducteur Tbk accepte la chaîne vide. Le transducteur Tbk peut alors émettre des balises de début et fin de BCK de manière anarchique dans la phrase analysée. Pour éviter cela nous modifions l’accepteur AF afin de lui imposer l’analyse d’au moins un mot, voir figure 5.5.
Le modèle Filler pouvant re-boucler sur lui même dans la topologie illustrée dans la figure 5.4, l’analyse
d’une chaîne de mots non-conceptuelle (e.g. « euh oui alors euh ») peut amener à différentes
segmentations, car plusieurs chemins dans le transducteur existent :
<BCK> euh oui alors euh </BCK>
<BCK> euh </BCK> <BCK> oui alors euh </BCK>
<BCK> euh oui </BCK> <BCK> alors </BCK> <BCK> euh </BCK>
…
Or, la segmentation désirée est celle qui analyse d’un bloc la séquence de mots non conceptuelle :
<BCK> euh oui alors euh </BCK>
Pour obtenir ce résultat la topologie du modèle conceptuel a été revue : le modèle Filler ne re-boucle plus
sur lui même. Seule une séquence de mots conceptuelle peut suivre. On force donc l’analyse
d’une séquence de mots « background » a être effectuée entièrement dans le Filler (figure
5.6).
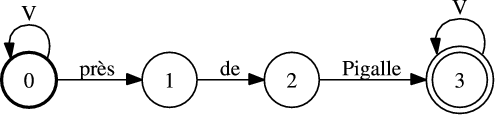
Un dernier inconvénient dû au Filler, est qu’il reconnaît toutes les séquences de mots (V ∗) composées à partir du vocabulaire, y compris les séquences de mots conceptuelles. L’analyse d’une séquence de mots conceptuelle par notre modèle conceptuel va donner lieu à une double segmentation. Supposons que notre modèle conceptuel Tconcept ne modélise qu’un seul concept de LIEU et que l’automate ALIEU représentant ce concept ne modélise qu’une règle : « près de Pigalle », comme illustré à la figure 5.7.
La chaîne de mots, « euh oui alors euh près de pigalle » va être analysée de 2 façons différentes par
Tconcept :
<BCK> euh oui alors euh </BCK> <LIEU> près de Pigalle </LIEU>
<BCK> euh oui alors euh près de Pigalle </BCK>
Pour supprimer cette double analyse tous les chemins dans les accepteurs Ak sont supprimés du modèle
Filler AF de la manière suivante :
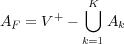 | (5.3) |
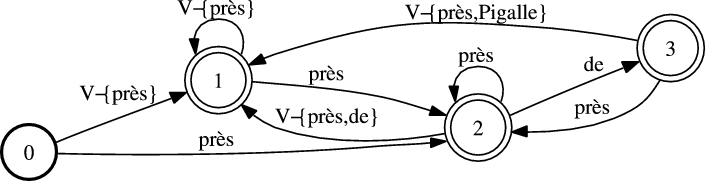
Dans l’exemple représenté en figure 5.8 toutes les séquences de mots incluant une séquence conceptuelle sont retirées du Filler (figure 5.5). Nous obtenons un modèle Filler ne pouvant accepter les séquences de mots conceptuelles (figure 5.9).
Les différents automates conceptuels reconnaissent les séquences de mots relatives au concept qu’ils modélisent. Certaines séquences de mots extraites d’un corpus, peuvent partager les mots qui les composent, mais ont des tailles différentes en raison de la variabilité des expressions employées par les utilisateurs. Le tableau 5.2 montre un même concept, en l’occurrence de lieu, exprimé de plusieurs manières plus ou moins concises.
|
Dans cet exemple, certaines séquences de mots sont des sous-chaînes d’autres séquences. Certaines
d’entre elles se chevauchent. Toutes ces séquences sont le produit de chemins parcourus dans l’accepteur
modélisant le concept. Dans le cas où la chaîne à analyser contiendrait le contexte le plus long, plusieurs
chemins dans Tconcept existent. En effet, même si ces séquences présentées dans le tableau 5.2, ont
été supprimées des chemins acceptés par le Filler, les sous-séquences comme « dans » ou
« arrondissement » sont acceptées et à juste titre, vu qu’elles ne représentent pas à elles seules un
concept. Plusieurs segmentations sont alors données par Tconcept pour une même séquence de
concepts :
<LIEU> dans le neuvième arrondissement de Paris </LIEU>
<LIEU> dans le neuvième arrondissement </LIEU> <BCK> de Paris </BCK>
<BCK> dans </BCK> <LIEU> le neuvième arrondissement </LIEU> <BCK> de Paris </BCK>
<LIEU> dans le neuvième </LIEU> <BCK> arrondissement de Paris </BCK>
Or, nous voulons laisser les segmentations multiples seulement dans le cas ou ces segmentations amènent
à des interprétations différentes de la phrase à analyser. Ceci peut arriver dans le cas d’une ambiguïté
sémantique qui ne peut être levée à ce niveau du processus. Par exemple « le neuvième » sans contexte
peut faire référence à un arrondissement ou bien à une position dans une liste de restaurants.
Sans un contexte dans la phrase permettant de désambiguïser l’analyse, les deux analyses
possibles doivent être faites. C’est au gestionnaire de dialogue en fonction de l’historique du
dialogue de choisir la bonne. Dans le cas présenté ici, nous désirons supprimer des analyses
redondantes qui pour une même séquence de mots amènent à la même séquence de concepts (voir
remarque plus bas), et nous désirons conserver celle qui donne la segmentation au profit
de la plus longue séquence de mots représentant le concept (la no 1 dans cet exemple). Au
delà de ces considérations, ne conserver que le chemin le plus long dans l’automate permet
surtout de supprimer des ambiguïtés d’analyse en ce qui concerne les valeurs d’un concept.
Considérons les séquences observées dans le corpus pour le concept PRIX dans le tableau
5.3.
|
Le modèle Tconcept en l’état actuel, pour la chaîne « cent cinquante francs », va nous donner deux
analyses redondantes en terme de concept si l’on ne considère que les attributs, mais une fausse en terme
de valeur :
<BCK> cent </BCK> <PRIX> cinquante francs </PRIX>
<PRIX> cent cinquante francs </PRIX>
Or dans ce contexte seule la deuxième segmentation est correcte (voir remarque).
| Remarque : il est possible que le contexte désambiguïsateur soit incorrect (i.e. dû à une erreur de reconnaissance) on pourrait donc penser dans ce cas qu’il faille conserver la segmentation donnant lieu à un autre concept ou une autre valeur pour un concept. Mais comme nous travaillons sur l’analyse du graphe de mots, nous faisons la supposition que si les mots formant le contexte sont proposés à tort par le système RAP, au moins un chemin (et dans la pratique plusieurs) du graphe ne les contient pas et fournira l’interprétation correcte. |
Pour chaque concept Ck, nous dressons la liste des séquences de mots qui sont incluses dans d’autres et nous générons un transducteur TForbiddenPath(k) qui dresse la liste des segmentations indésirables. En considérant les accepteurs conceptuels illustrés en figure 5.1 et 5.2, les transducteurs 5.10 et 5.11 illustrent les transducteurs TForbiddenPath(Ck) associés.
Ces transducteurs contiennent tous les chemins possibles conduisant à ces segmentations incorrectes. Dans les transducteurs, les transitions « entrée :sortie » sont de la forme « 𝜖 :étiquette_conceptuelle » ou « mot :𝜖 » (les transitions 𝜖 sont notées NULL dans les différentes figures), pour simplifier l’écriture nous ne considérons que la sortie dans le premier cas et l’entrée dans le second. Les chemins non-désirés sont alors représentés par l’expression régulière suivante :
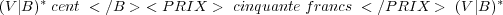
Le même procédé est appliqué aux séquences de mots qui se chevauchent, seule la segmentation autour de la séquence la plus longue est conservée. En cas d’égalité, la première séquence apparaissant dans la phrase à analyser est gardée. Si le chevauchement est important, on peut supposer que la séquence de mots composée à partir de deux séquences est une séquence valide pour exprimer le concept. Si cette séquence ne fait pas partie des règles, alors des problèmes peuvent se poser lors des suppressions de chemins : une séquence de mots n’est plus analysée par notre modèle car plus aucun chemin n’existe dans Tconcept. Cela peut être le cas dans l’exemple suivant : soient 3 règles associées à la détection d’un concept (tableau 5.4), en l’occurrence SPÉCIALITÉ, et la chaîne de mots reconnue « un restaurant diététique marocain ».
|
Dans le modèle Tconcept ont été supprimés plusieurs chemins : premièrement, aucune des séquences ne
peut être analysée par le modèle Filler ; deuxièmement, dans le contexte de la séquence 2, la
segmentation autour de « marocain » avec le concept de SPÉCIALITÉ n’est plus possible ; enfin dans un
contexte où apparaissent les séquences 1 et 2, la segmentation, avec le concept de SPÉCIALITÉ, autour
de la séquence 2 est supprimée (ceci étant dû au chevauchement de ces 2 séquences, la première
est conservée). Dans un contexte où apparaîtrait la séquence « un restaurant diététique
marocain 1 » :
toutes les segmentations deviennent impossibles car cette séquence ne fait plus partie du langage reconnu
par Tconcept :
<BCK> un restaurant diététique </BCK> <SPEC> marocain </SPEC>  Segmentation interdite : la séquence 1 a été soustraite du modèle Filler
Segmentation interdite : la séquence 1 a été soustraite du modèle Filler
<BCK> un </BCK> <SPEC> restaurant diététique marocain </SPEC>  Segmentation interdite : on a privilégié la séquence 1 sur la séquence 2 :
Segmentation interdite : on a privilégié la séquence 1 sur la séquence 2 :
Suppression de {.* un </B> <SPEC> restaurant diététique marocain </SPEC>}.
<SPEC> un restaurant diététique </SPEC> <SPEC> marocain </SPEC>  Segmentation impossible : en raison des séquences 2 et 3, toutes les chaînes de type :
Segmentation impossible : en raison des séquences 2 et 3, toutes les chaînes de type :
{.* restaurant <(B|/B)> ? diététique </B> <SPEC> marocain </SPEC>} sont supprimées.
En fait, ces situations se produisent, lorsque nous avons deux règles qui se chevauchent (ici la séquence 1 et 2), et que celle qui n’est pas privilégiée (la 2) présente une inclusion dans une règle virtuelle qui serait obtenue par la concaténation de la règle privilégié (la 1) et d’une autre dans le modèle (ici la 3) :
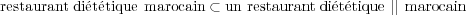
Or dans ces cas là, il est légitime de penser que cette règle virtuelle est valide pour représenter le concept ; comme solution, il a donc été choisi de l’ajouter. Une règle construit selon ce principe est, soit pertinente et dans ce cas lorsque la séquence de mots apparaît, il n’y a plus de segmentations impossibles, la segmentation se fait autour de cette nouvelle règle ; soit elle n’est pas pertinente, et alors la séquence de mots (relativement longue) a peu de chances d’apparaître et le fait que cette règle existe dans le modèle, même si elle n’est pas utile, ne perturbe pas l’analyse.
Certaines règles peuvent être partagées par plusieurs concepts lorsqu’elles sont ambiguës. Par exemple la séquence de mots : « le deuxième » sans autre contexte peut faire référence à un lieu (le deuxième arrondissement) ou à une liste (le deuxième restaurant). Sans un contexte désambiguisateur, les deux concepts doivent être détectés et c’est au module de compréhension en fonction de ses connaissances sur l’historique du dialogue de prendre une décision sur la validité de l’un ou de l’autre. Au contraire, en présence de ce contexte, seul le bon concept doit être détecté. Le même procédé que dans la section 5.5.6 est appliqué entre les concepts pouvant être ambigus, afin d’éviter la génération du mauvais concept en présence d’un contexte clair. Exemple tableau 5.5. Le modèle ne génère plus le concept LIEU en présence du contexte droit « restaurant » et le concept LISTE en présence du contexte droit « arrondissement ».
| ||||||||||||||||||||||||||||||
Le processus de décodage proposé aboutit à la création d’une liste structurée des N-meilleures hypothèses. En guise d’illustration, nous donnons ici un exemple simplifié.
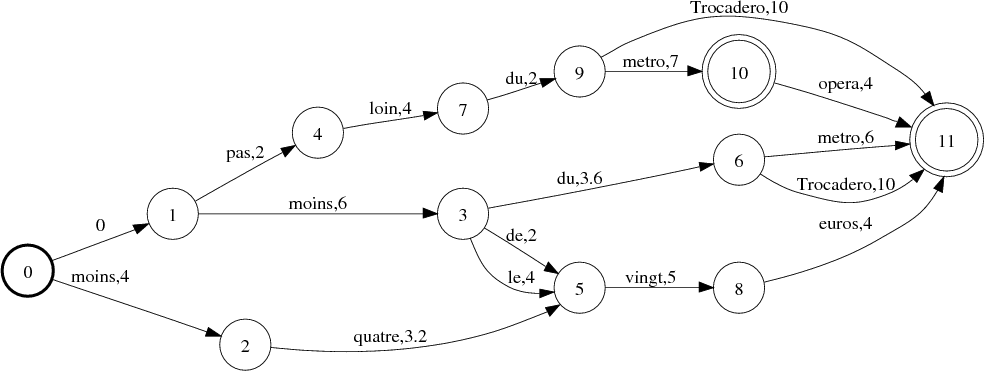
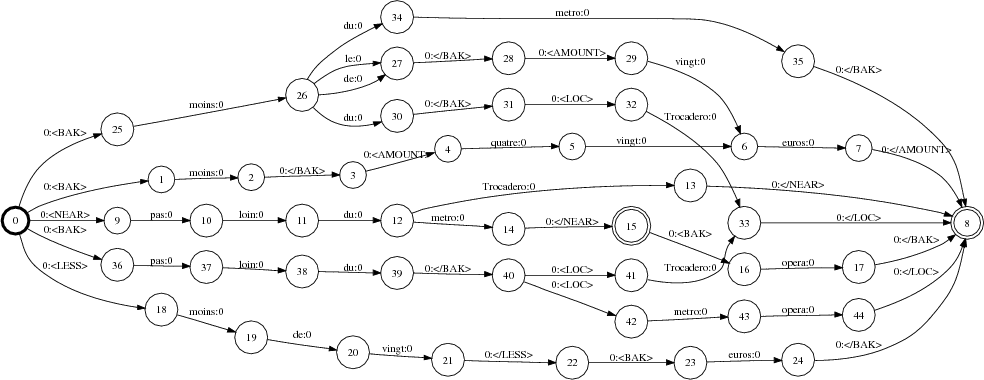
Lors d’un traitement d’une intervention utilisateur, le module de reconnaissance génère un graphe de mots codé en tant qu’accepteur GW. Le semi-anneau utilisé est le log semiring (voir tableau 3.2) et la fonction w(π) correspond au log des scores P(A|W)P(W) où A est la séquence d’observations acoustiques, W la chaîne de mots représentant le chemin π, P(A|W) la probabilité donnée par le modèle acoustique et P(W) la probabilité donnée par le modèle de langage. Un exemple de GW est observable à la figure 5.12. Les scores attachés à chaque transition sont donnés en −logprob.
GW est composé avec le transducteur TConcept dans le but d’obtenir le transducteur mots-concepts
TWC : TWC = GW ∘ TConcept, illustré dans la figure 5.13.
| Remarque : Dans l’espace de recherche TWC il est maintenant possible de faire intervenir des connaissances sur l’agencement des concepts ou/et sur les prédictions des concepts à venir du système en fonction de l’état du dialogue. |
|
|
Dans cet exemple, nous considérons 4 types de constituants conceptuels : les fonctions NEAR (pour un
lieu) et LESS (pour un montant) ainsi que les étiquettes LOC pour les lieux et AMOUNT pour les valeurs
monétaires. Ces constituants sont représentés par les patrons suivants dans cet exemple :
avec $NAME un nom propre et $NUMBER toute expression correspondant à un nombre.
Un chemin Path(I,x,y,F) dans TWC (avec I l’état initial et F un état final de TWC) est une chaîne de mots si l’on considère seulement les symboles d’entrée x ou une séquence de concepts si l’on considère les symboles de sortie y. Dans le but d’obtenir toutes les interprétations possibles contenues dans GW, nous projetons TWC sur les symboles de sortie, puis nous déterminisons et minimisons le FSM résultant. L’accepteur obtenu est appelé GC. Comme l’opération est effectuée sur le log semiring, le poids du chemin Path(I,y,F) est la somme des poids de tous les chemins dans TWC qui produisent y :
 = [TW C](x,y)
x](these_v1.0100x.png) | (5.4) |
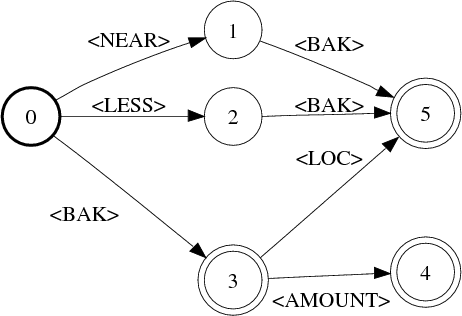
Un exemple de GC, obtenu à partir du transducteur TWC de la figure 5.13 est visible dans la figure 5.14. Pour des raisons de clarté, nous avons omis les balises de fin de concept.
|
|
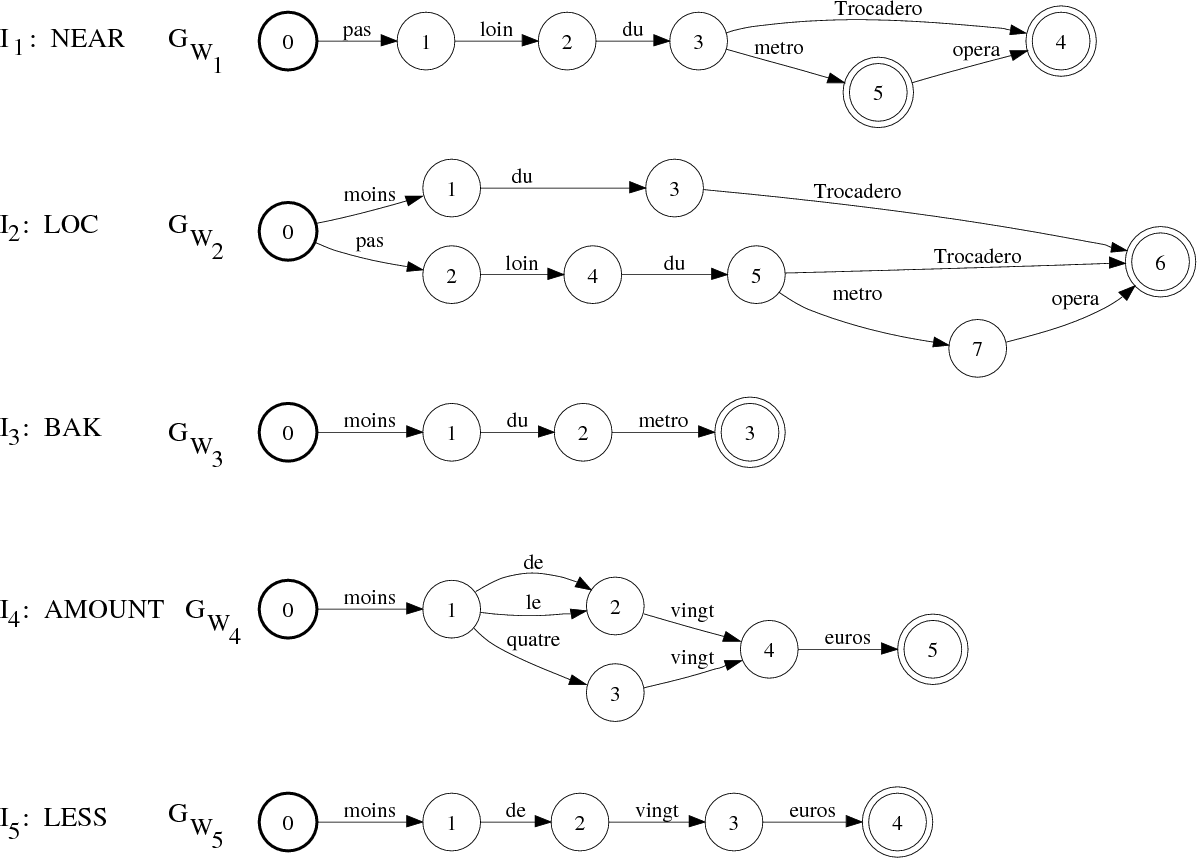
La liste des N-meilleures interprétations conceptuelles I1,I2,…,In est obtenue en changeant le semi-anneau dans GC, du « log semiring » au « tropical semiring » (voir tableau 3.2), puis nous énumérons les n meilleurs chemins S1, S2,…Sn dans GC. Chaque interprétation Ii est une chaîne d’étiquettes γ représentée par un accepteur Si avec le vocabulaire dans Γ. À chaque Ii est également attachée un accepteur GWi qui contient l’ensemble des chemins dans TWC qui émet la chaîne Ii : [GWi] = [TWC ∘ Si]. Ceci est représenté dans 5.15.
|
|
Cet ensemble de chaînes de concepts est la première étape du processus de génération de la N-meilleure liste structurée d’hypothèses Lnbest qui est la sortie finale de notre architecture de décodage.
Il est à noter que les séquences de mots associées à différents concepts peuvent se chevaucher. En effet, les mots exprimant le sens d’une fonction peuvent être essentiels ou très utiles pour décider qu’un nom propre indique de manière non-ambiguë un lieu, par exemple, plutôt qu’un autre type d’entité, voir l’exemple plus bas. Un certain niveau de redondance peut aussi être très utile pour compenser les erreurs de reconnaissance. En raison de ce chevauchement, certains concepts (comme NEAR et LOC dans notre exemple) sont dans différentes interprétations (I1 et I2 dans la figure 5.15). Ceci est le second niveau dans notre processus de compréhension qui tente de fusionner, si c’est possible, ces concepts en appliquant des relations sémantiques, comme présenté dans la section suivante.
Il est à noter que ce processus a un impact négligeable sur la rapidité du décodage car les opérations
sur les automates et transducteurs sont rapides.
| exemplechevaucheExemple : prenons la séquence de mots : « le deuxième restaurant italien », l’interprétation correcte associée est [< Accès_Liste_Restaurant :deuxième >< Spécialité :italien >]. Or, les valeurs seules de chaque concept ne sont pas caractéristiques des concepts qui doivent être détectés. Elles sont ambiguës sans la présence du mot restaurant. En effet « deuxième » sans contexte peut faire référence soit à un lieu (e.g. « deuxième arrondissement »), soit à une valeur d’accès à une liste et peut déclencher les deux concepts associés. « italien » seul peut faire référence à la spécialité culinaire où à un lieu (e.g. « quartier italien ») et déclencher les concepts de Spécialité et de Lieu. Le contexte désambigüisateur est pour les deux cas le mot « restaurant » qui doit être présent dans les deux règles permettant de détecter les concepts de l’interprétation : cela implique que les règles doivent se chevaucher |
Une fois que les constituents conceptuels ont été extraits, des relations sémantiques doivent être identifiées et utilisées pour instancier des structures sémantiques et faire de l’inférence. Il est à noter que les relations doivent avoir un support dans le graphe d’hypothèses de mots et le résultat de l’inférence également. Le support de la relation inférée est l’intersection des supports des interprétations basiques qui sont utilisées dans la relation d’inférence.
Une partie des connaissances sémantiques est faite d’implications exprimant des règles de constructions. Pour des raisons de clarté, un exemple d’inférence utilisant ces règles sera développé dans cette section. En utilisant la notation proposée dans [Jackendoff, 1990] la catégorie path est inférée par la règle suivante :
![⌊ (| TO )| ⌋
| |||{ FROM |||} ([{ } ]) |
|| NEAR THING ||
[PAT H]→ || ||| TOW ARD ||| PLACE ||
|⌈ |( ... |) |⌉
path](these_v1.0103x.png)
La règle établit que, par exemple, la composition de la fonction NEAR avec une instance de PLACE donne une instance de PATH. Toute composition obtenue est une structure sémantique correcte. Les règles de composition peuvent être utilisées dans des représentations sémantiques de structures plus complexes comme dans KLONE [Levesque et Brachman, 1985].
Par inférence, une instance de <PATH> : ⌊pathNEAR(⌊placeIN(⌊thingLOC⌋)⌋)⌋ peut être supputée par la présence d’hypothèses de la fonction NEAR et une instance de <PLACE>.
Si l’hypothèse NEAR est représentée avec l’accepteur GWNEAR et <PLACE> avec l’accepteur GWPLACE (obtenus avec la méthode présentée dans la section précédente), alors l’hypothèse GWPATH pour une instance de <PATH> est générée si et seulement si :
GWPATH = [GWNEAR ∩ GWPLACE]≠∅
Si la nouvelle structure sémantique générée rend possible l’application de nouvelles règles de composition, l’intersection des supports des constituants correspondants est appliquée et, si l’intersection n’est pas vide, la nouvelle structure sémantique inférée est ajoutée à l’ensemble des interprétations. Le processus est répété tant qu’il n’y a plus de compositions à effectuer.
À chaque structure sémantique Ii représentée par l’accepteur GWI i est attachée comme score la probabilité a posteriori suivante (avec X l’ensemble des chaînes acceptées par GWI i et Z l’ensemble des chaînes acceptées par WG) :

P(Ii|Y ) = ⊕z ∈Z[WG ](z)](these_v1.0104x.png) | (5.5) |
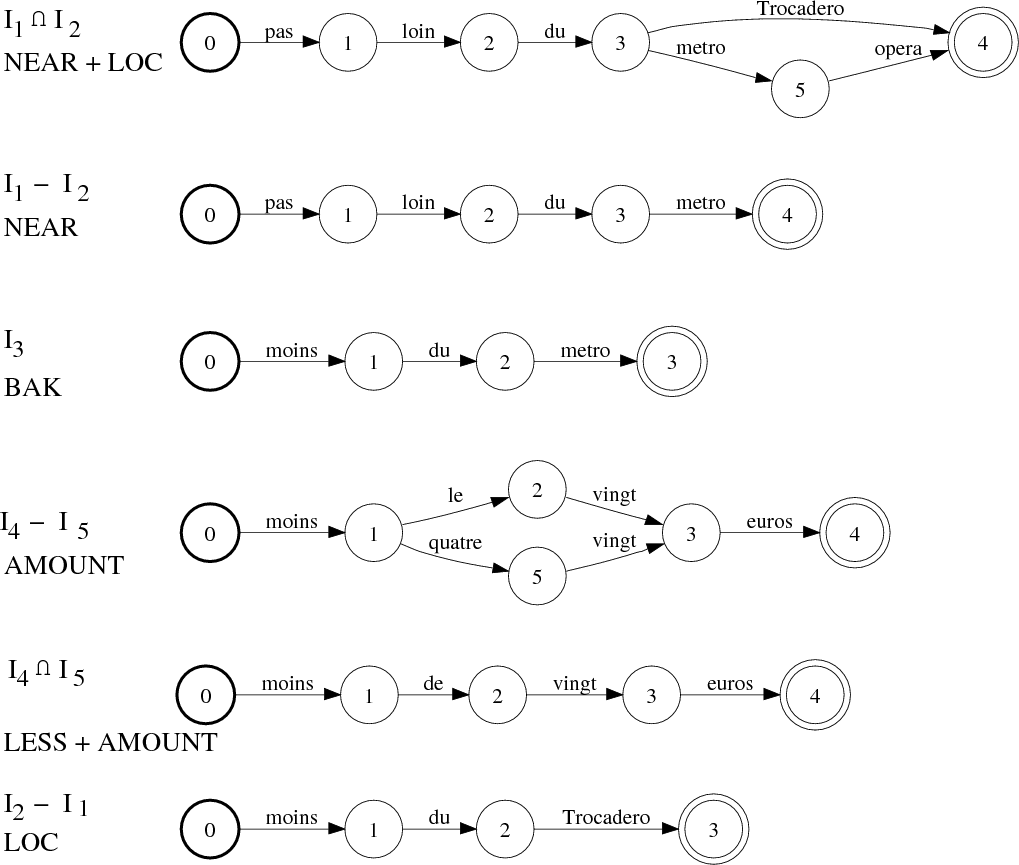
Par exemple, pour les 5 interprétations de la figure 5.15, 2 relations sémantiques peuvent être appliquées :
Ceci amène à faire 6 opérations sur les accepteurs GWi :
![GWI1∩I2 = [GW1 ∩ GW2] → NEAR + LOC
GWI1−I2 = [GW1 − GW2 ] → NEAR
GWI2−I1 = [GW2 − GW1 ] → LOC
GWI4∩I5 = [GW4 ∩ GW5] → AM OU N T + LESS
GWI −I = [GW4 − GW5 ] → AM OU N T
GWI4−I5= [GW5 − GW4 ] → LESS
5 4](these_v1.0105x.png)
Comme GWI 5−I4 = ∅, seulement 6 interprétations sont conservées : les 5 premières obtenues plus l’interprétation I3 (BAK) qui n’a été impliquée dans aucune opération. Ces interprétations sont associées à un score en accord avec leur probabilité a posteriori. Sur le FSM de la figure 5.12, nous obtenons :
|
|
La figure 5.16 montre les 6 interprétations conservées avec leur FSMs correspondant.
La dernière étape dans le processus de compréhension génère la liste des N-meilleures hypothèses en termes de valeur pour chaque hypothèse conceptuelle. Plusieurs valeurs peuvent être trouvées dans un FSM pour le même concept. C’est particulièrement vrai, quand les concepts représentent des entités numériques comme des numéros de téléphone ou des montants. Il est alors possible de générer pas seulement la meilleure chaîne de mots pour chaque interprétation Ii, mais plutôt la liste des N-meilleures chaînes de mots conduisant à des valeurs conceptuelles différentes.
L’extraction des N-meilleures valeurs peut être très utile dans un contexte de dialogue, ainsi que d’autres informations additionnelles (données clients, contraintes sur les valeurs, etc.) pour pouvoir sélectionner une valeur à l’intérieur d’une liste d’hypothèses. Par exemple [Rahim et al., 2001] montrent que le fait d’utiliser un annuaire de téléphone pour filtrer automatiquement les numéros de téléphone de la liste des N-meilleurs candidats est très efficace : l’exactitude de la reconnaissance des chaînes de mots qui appartiennent à l’annuaire est de 94.5% (cela représente 61% des hypothèses) comparée à seulement 45% pour celles qui ne peuvent être trouvées dans un annuaire.
Ainsi, l’accepteur GWi attaché à chaque interprétation Ii est composé avec un transducteur qui émet seulement les différentes valeurs (principalement les noms propres et les valeurs numériques) contenues dans le FSM. Les N-meilleures valeurs ainsi que la chaîne de mots support correspondante sont associées à chaque Ii dans le but de construire une liste structurée des N-meilleures interprétations sémantiques (Lnbest).
La liste structurée des N-meilleures correspondant à notre exemple est présentée dans le tableau 5.6.
|
La liste structurée des N-meilleures hypothèses peut être vue comme le résumé de toutes les interprétations possibles d’une intervention utilisateur. Les 2 principaux avantages de cette liste structurée comparée à une liste standard sont les suivants :
Des expériences ont été menées sur l’enrichissement de l’espace de recherche au moyen de notre modèle de langage conceptuel construit à partir de la totalité des 59 concepts utilisés par France Télécom dans l’application PlanResto (section 4.2.4).
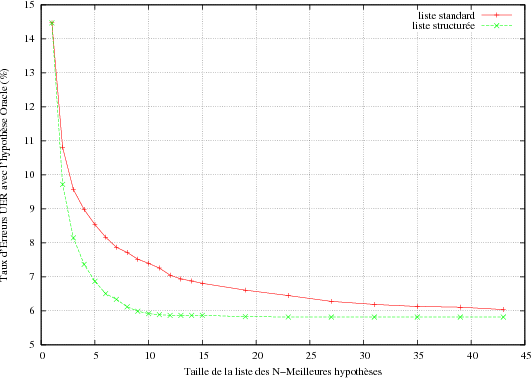
L’intérêt principal de la liste structurée est qu’elle permet de résumer un graphe de mots sans perdre d’informations. Elle propose en effet toutes les interprétations existantes dans le graphe, sans redondance, accompagnés des meilleures transcriptions les supportant. De ce fait, la liste structurée pour une taille équivalente permet de converger plus vite que la liste standard vers l’UER optimal qu’il est possible de trouver dans le graphe de mots du fait de l’absence de redondance au niveau conceptuel. Si l’on recherche dans une liste des N-meilleures hypothèses, l’hypothèse ayant le plus faible taux d’erreurs UER (taux Oracle) (voir figure 5.17) la liste structurée permet dès N = 10 d’obtenir l’UER le plus faible qui existe dans le graphe tandis qu’il faut N > 40 dans le cas d’une liste standard. L’écart est en rapport avec le nombre de concepts utilisés pour guider le décodage de la transcription. D’autres expériences ne faisant intervenir que les 3 principaux concepts avec valeur de l’application (i.e. Spécialité, Lieu, Prix) pour guider le processus de transcription donnent lieu à une convergence vers le plus faible taux UER dès la troisième interprétation, c.f. tableau 5.7.
|
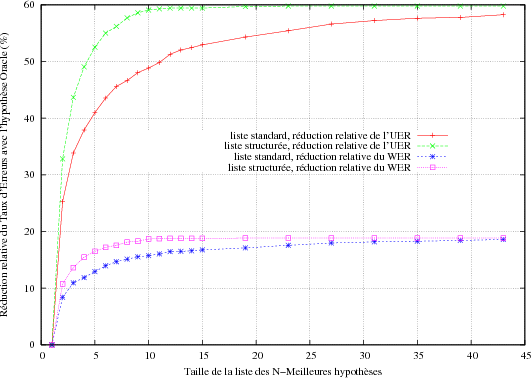
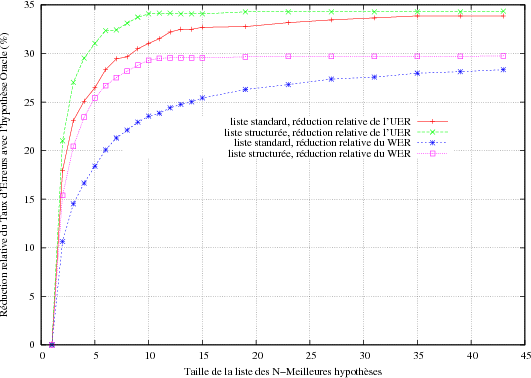
Même si le WER et l’UER sont fortement corrélés, une réduction relativement forte de l’UER, n’induit pas une réduction du même niveau pour le WER. La (figure 5.18) montre le gain obtenu sur les taux d’erreurs WER et UER lorsque on sélectionne la meilleure hypothèse selon le critère de l’UER dans la liste. La réduction de l’UER va culminer à 60% tandis que le WER n’a été réduit que de 20%, ce qui tend à prouver le fait que tous les mots d’une phrase ne sont pas utiles pour la compréhension et que des informations linguistiques de niveau supérieur doivent être prises en compte. Réciproquement, en cherchant pour la meilleure hypothèse oracle selon le critère du WER (courbe 5.19), la réduction obtenu en WER passe rapidement à 30% contre 20% sur la courbe 5.18 mais la réduction sur l’UER culmine à 35% au lieu de 60%. L’optimisation d’un décodage en vue d’un meilleur taux d’erreurs mot n’implique pas obligatoirement un meilleur taux d’erreurs en compréhension. Dans tous les cas la liste structurée permet de converger plus vite vers la meilleure hypothèse que la liste standard grâce à l’absence des redondances. Un exemple de liste structurée utilisant les 59 concepts (voir section 4.2.4) de l’application PlanResto est présentée dans la figure 5.20. Le nombre en face de chaque transcription indique sa position dans une liste des N-meilleures standard.
|
|
|
|
|
|
Nous avons présenté l’implémentation d’un modèle conceptuel qui permet d’enrichir un graphe de mots des concepts utilisés par une application de dialogue. Ce modèle assure la détection de concepts autorisant les règles associées à chaque concept à partager des mots. Il effectue également, à son niveau, une première désambiguïsation conceptuelle. Une fois le graphe de mots enrichi conceptuellement, il est possible de faire des recherches guidées par les prédictions du gestionnaire de dialogue en plus des connaissances acoustiques et linguistiques. L’architecture de décodage proposée offre un moyen élégant et efficace de passer du graphe de mots au graphe de concepts. La sortie de reconnaissance fournit de manière automatique l’interprétation (séquence de concepts) d’une hypothèse. Ceci nous permet de générer une liste structurée sémantiquement des N-meilleurs candidats. Cette liste structurée met en compétition des hypothèses qui ne sont pas redondantes du point de vue du gestionnaire de dialogue car elles donnent lieu à des interprétations différentes. Nous avons montré à travers des mesures Oracle que la vraisemblance donnée par un système de RAP dans le choix d’une hypothèse n’est pas un critère optimal. La liste structurée propose très souvent, avec un nombre de candidats réduit, la solution optimale pour le module de compréhension. Le chapitre suivant propose un ensemble de mesures de confiance utiles pour diagnostiquer le résultat produit par notre décodage.