



Next: Random Neural Networks (RNN)
Up: Neural Networks
Previous: Neural Networks
Contents
Index
Artificial Neural Networks (ANN)
An ANN is a parallel distributed associative processor, comprised of multiple elements (neural models) highly interconnected [117,149,150,118]. Each neuron carries out two operations. The first is an inner product of an input vector (carrying signals coming from other neurons and/or other inputs) and a weight vector, where the weights represent the efficiencies associated with those connections and/or from external inputs. The second, for each neuron, a nonlinear mapping between the inner product and a scalar is to be computed, usually given by a non-decreasing continuous function (e.g., sigmoid, or
tanh). When building ANN, an architecture and a learning algorithm must be specified. There are multiple architectures (e.g., multi-layer feedforward networks, recurrent networks, bi-directional networks, etc.), as well as learning algorithms (e.g., Backpropagation, Kohonen's LVQ algorithm, Hopfield's algorithm, etc.).
As pattern classifiers, ANN work as information processing systems that search for a non-linear function mapping from a set 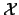 of input vectors (patterns) to a set
of input vectors (patterns) to a set 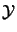 of output vectors (categories). This mapping is established by extracting the experience embedded in a set of examples (training set), following the learning algorithm. Thus, in developing an application with ANN, a set of
of output vectors (categories). This mapping is established by extracting the experience embedded in a set of examples (training set), following the learning algorithm. Thus, in developing an application with ANN, a set of 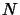 known examples must be collected, and represented in terms of patterns and categories (i.e., in pairs
known examples must be collected, and represented in terms of patterns and categories (i.e., in pairs 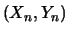 ,
,
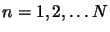 , where
, where
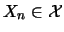 and
and
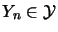 ). Then, an appropriate architecture should be defined. Last, a learning algorithm needs to be applied in order to build the mapping.
Highly nonlinear mappings can be obtained using the backpropagation algorithm for learning and adaptation, and a three-layer feedforward neural network consisting of an input layer, a hidden layer and an output layer.
). Then, an appropriate architecture should be defined. Last, a learning algorithm needs to be applied in order to build the mapping.
Highly nonlinear mappings can be obtained using the backpropagation algorithm for learning and adaptation, and a three-layer feedforward neural network consisting of an input layer, a hidden layer and an output layer.
Figure 3.1:
Architecture of a three-layer feedforward neural network.
|
|
In this architecture (see Figure 3.1), external inputs are the inputs for the neurons in the input layer. The scalar outputs from those neural elements in the input layer are the inputs for the neurons in the hidden layer. The scalar outputs in the hidden layer become, in turn, the inputs for the neurons in the output layer.
When applying the backpropagation algorithm, all the weights' initial values are given randomly. Then, for each pair in the database, the vector 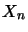 (i.e., pattern) is placed as input for the input layer, and the process is carried out forward through the hidden layer, until the output layer response
(i.e., pattern) is placed as input for the input layer, and the process is carried out forward through the hidden layer, until the output layer response 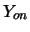 is generated. Afterwards, an error
is generated. Afterwards, an error 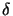 is calculated by comparing vector
is calculated by comparing vector 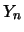 (classification) with the output layer response, . If they differ (i.e., if a pattern is misclassified), the weight values are modified throughout the network accordingly to the generalized delta rule:
(classification) with the output layer response, . If they differ (i.e., if a pattern is misclassified), the weight values are modified throughout the network accordingly to the generalized delta rule:
where, 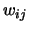 is the weight for the connection that neuron
is the weight for the connection that neuron 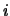 , in a given layer, receives from neuron
, in a given layer, receives from neuron 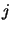 from the previous layer;
from the previous layer; 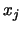 is the output of neuron in that layer;
is the output of neuron in that layer; 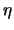 is a parameter representing the learning rate; and is an error measure. In case of the output layer,
is a parameter representing the learning rate; and is an error measure. In case of the output layer,
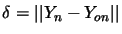 , whereas in all hidden layers, is an estimated error, based on the backpropagation of the errors calculated for the output layer (for details refer to [117,118]). In this way, the backpropagation algorithm minimizes a global error associated with all pairs , where
in the database. The training process keeps on going until all patterns are correctly classified, or a pre-defined minimum error has been reached.
, whereas in all hidden layers, is an estimated error, based on the backpropagation of the errors calculated for the output layer (for details refer to [117,118]). In this way, the backpropagation algorithm minimizes a global error associated with all pairs , where
in the database. The training process keeps on going until all patterns are correctly classified, or a pre-defined minimum error has been reached.
Next: Random Neural Networks (RNN)
Up: Neural Networks
Previous: Neural Networks
Contents
Index
Samir Mohamed
2003-01-08
![\fbox{\includegraphics[width=10cm]{Figs_1A/Fig-5}}](img194.gif)