



Next: General Conclusions of this
Up: New Random Neural Network
Previous: Learning Performance in the
Contents
Index
In this Chapter, we have proposed two new training algorithms for RNN. The first one is based on the Levenberg-Marquardt method for ANN. This algorithm is one of the most powerful training algorithms in ANN in terms of performance (time required to converge, precision, number of iteration, etc.) for a given problem. The second one is an improvement of the Levenberg-Marquardt method. It introduces the adaptive momentum to further accelerate and enhance the training process by adding the information of the second order derivatives to the cost function. We have studied these two algorithms and we have provided the steps and mathematical derivation for them to be used with RNN.
We have evaluated the performance of these algorithms against the most widely available one for RNN, namely the gradient descent one. The experimental results clearly show the improvement and efficiency obtained by the new techniques.
Our work in this area has been motivated by two reasons. First, as
explained in Chapter 6, RNN behaves better in our problems
(including the multimedia quality assessment) than ANN. Second,
the available training algorithm for RNN, namely the gradient descent
which is very general, can, in some cases, converge very slowly to the solution. In addition, it suffers from the zigzag problem. ANNs have been studied intensively and there are many training algorithms available for them. Naturally, we have chosen the most powerful algorithms, to the best of our knowledge, for ANN and we adapted them to RNN.
However, it is known that Levenberg-Marquardt methods can converge to local minima in some cases depending on the initialization of the weights. One simple solution to this problem is to restart the training process whenever a local minimum convergence has taken place but by initializing the weights differently. As shown by our results, when the proposed algorithms converge to the global minimum, they converge very fast. For example, it takes only one or two iterations to reach 0 error in the XOR problem. More sophisticated solutions can be studied in the future, for instance combining the Levenberg-Marquardt methods with the ``simulating annealing'' technique which is based on a well-studied mathematical model.
Another point that deserves attention in future research work is the study of the best ranges of the learning parameters (namely,
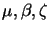 and
and 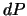 ), etc.
), etc.
Next: General Conclusions of this
Up: New Random Neural Network
Previous: Learning Performance in the
Contents
Index
Samir Mohamed
2003-01-08