
This page is divided into the following sections:
The target grammars, training and testing sentences were created with the following objectives in mind:
From (Gold 1967 ) it is known that it is impossible to learn a context-free grammar from positive examples only without reference to a statistical distribution, however:
Therefore it was decided to include problems that included learning grammars from positive examples as well as learning grammars from positive as well as negative examples.
To determine whether or not requirement1 was met, a measure of the complexity of the learning task was derived. The measure was derived by creating a model of the learning task based upon a brute force search (The BruteForceLearner algorithm). This model was also used to determine if the training data was sufficient to identify the target grammar. This model of learning including the derivation of the complexity formulae is defined here .
The summary of these proofs is that
For reasons described in the previous section, the following equation was used a measure of the complexity of the learning task. This measure was applied to a characteristic set of the target grammar.
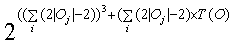
Given this knowledge the following technique was used to construct the training sets for the Omphalos competition;
The number of training examples was selected to be between 10 and 20 times as large as the characteristic set.
Firstly the literature was reviewed to identify pre-existing benchmark grammatical inference problems. The work of Stolcke (Stolcke 1993 ) and (Nakamura and Matsumoto 2002 ) identified some benchmark problems from Cook, Rosenfield et al. (1976 ) and Hopcroft, Motwani et al. (2001 ) .
Using Equation 1 the complexity of these grammars were measured. A description of these grammars and their complexity measures are listed in Table 1 below . The complexity measure was applied to a characteristic set of the target grammar, rather than the complete training sets.
Table 1 Complexity of Benchmark Inference Problems from Stolcke (Stolcke 1993 ) and (Nakamura and Matsumoto 2002 )
|
Grammar |
Description |
Example phrase |
Log 2 (Complexity)
|
Properties of Language |
|
1 |
(a2)* |
aa, aaaa, aaaaaa |
1.34E+03 |
Regular |
|
2 |
(ab)* |
ab,abab,ababab |
2.22E+03 |
Regular |
|
3 |
Operator precedence (small) |
(a + (b +a)) |
9.37E+03 |
Not regular |
|
4 |
Parentheses |
( ), (( )), () (), ()(()) |
2.22E+03 |
Not regular |
|
5 |
English verb agreement (small) |
that is a woman, i am there |
5.33E+05 |
Finite |
|
6 |
English lzero grammar |
a circle touches a square, a square is below a triangle |
4.17E+06 |
Finite |
|
7 |
English with clauses (small) |
a cat saw a mouse that saw a cat |
6.59E+05 |
Not regular |
|
8 |
English conjugations (small) |
the big old cat heard the mouse |
9.13E+05 |
Regular |
|
9 |
Regular expressions |
a b * ( a )* |
9.39E+03 |
Not regular |
|
10 |
{ w = w R , w Î {a,b}{a,b}+} |
a a a, b a |
6.90E+04 |
Not regular |
|
11 |
Number of a’s = number of b’s |
a a b b a a |
4.29E+04 |
Not regular |
|
12 |
Number of a’s = 2 ´ number of b’s |
a a b, b a b a a a |
3.01E+05 |
Not regular |
|
13 |
{ w w | w Î {a,b}+} |
a b a, a a |
9.12E+04 |
Regular |
|
14 |
Palindrome with end delimiter |
a a b b $, a b $, b a a b$ |
1.18E+05 |
Not regular |
|
15 |
Palindrome with centre mark |
a c a, a b c b a |
4.96E+03 |
Not regular |
|
16 |
Even length palindrome |
a a, a b b a |
9.30E+03 |
Not regular |
|
17 |
Shape grammar |
d a, b a d a |
2.45E+04 |
Not regular |
Using the results of Table 1 the complexity of the target grammars was selected. The grammars where then created as follows.
Using this technique ten grammars were created as listed below in Table 2 . Tests were undertaken to ensure that grammars 1-4 and 7-8 represented deterministic languages. To ensure that grammars 4,5,6,9 and 10 represented a non-deterministic language rules were added to the target grammars. It should be noted that these grammars are complex enough that they cannot be learnt using a brute force technique in time to be entered into the Omphalos competition. Having said that even the smallest of grammars could not be inferred using the BruteForceLearner .
Table 2 Complexities of Benchmark Inference Problems in Omphalos Competition.
|
Exercise |
Training examples available |
Properties of Language |
Log 2 (Complexity) |
|
1 |
Positive & negative |
Not regular, deterministic |
1.10E+09 |
|
2 |
Positive only |
Not regular, deterministic |
7.12E+08 |
|
3 |
Positive & negative |
Not regular, deterministic |
1.65E+10 |
|
4 |
Positive only |
Not regular, nondeterministic |
1.13E+10 |
|
5 |
Positive & negative |
Not regular, nondeterministic |
5.46E+10 |
|
6 |
Positive only |
Not regular, nondeterministic |
6.55E+10 |
| 7 |
Positive & negative | Not regular, deterministic | 5.88E+11 |
| 8 |
Positive only | Not regular, deterministic | 1.63E+11 |
| 9 |
Positive & negative | Not regular, nondeterministic | 1.08E+12 |
| 10 |
Positive only | Not regular, nondeterministic | 9.92E+11 |
The grammars listed in Table 2 represent two axes of difficulty in grammatical inference specifically
· The complexity of the underlying problem
· The amount of training data.
The competition has adopted a linear ordering for the benchmark problems based upon the complexity of the problems, and whether or not negative data is used to infer the grammar. For each level of complexity there are two problems. Solving the problem without using negative data is considered to be a more difficult problem. Therefore if both problems are solved, the competitor who has solved the problem without negative data will be declared the winner. In addition it has been noted by Nakamura that the inference of nondeterministic languages is a more difficult problem. This makes perfect sense given that knowing that the grammar is deterministic reduces the search space of the inference problem.
Once the target grammars were constructed characteristic sets were then constructed for each grammar. A set of positive examples were then created using the GenRGenS software (Denise, Sarron et al. 2001 ) . Additional examples were then created by randomly generating sentences of length less that 5+ the length of the longest sentence in the characteristic set. These sentences were then parsed using the target grammar and were labelled as being either in or out of the target language. This set of sentences was then randomised and split into testing and training sets, but in such a way as to ensure that the training set contained a characteristic set. For problems 2, 4 and 6 the training sets had all negative examples removed.
Omphalos is being organized and administered by:
Brad Starkie , François Coste and Menno van Zaanen
You can contact them for comments and complaints at omphalos@irisa.fr
![]()
![]()