proposed method
Trumpet
Bass
Drums
Voice
Sax
Bass
Piano
Brushes
Voice
Violin
F.Horn
Bass
Trumpet
Bass+Drums
Voice+Sax
Bass
Piano+Brushes
(of full-length recordings)
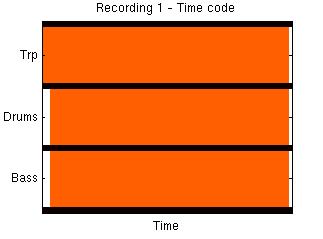
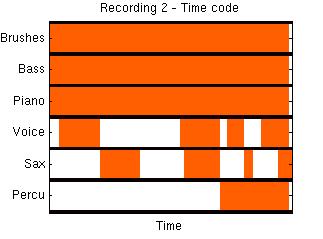
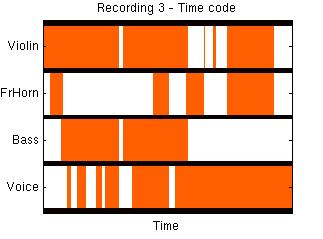
(of full-length recordings)
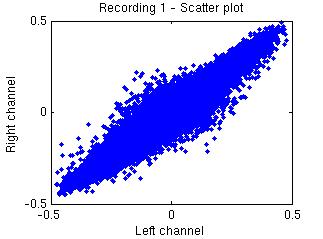
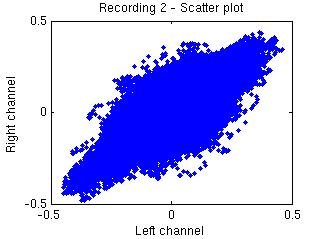
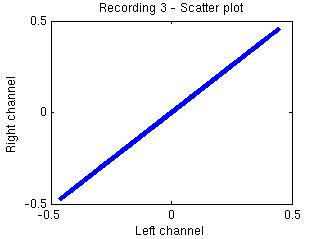
the sources separated
by the proposed method:
| C: | center |
| L/R: | left, right |
| Lf: | low frequency |
| Ls/Rs: | L/R surround |
| C | L | R | Lf | Ls | Rs |
| C | L | R | Lf | Ls | Rs |
| C | L | R | Lf | Ls | Rs |
SARAH