Direction des Relations Internationales (DRI)
Programme INRIA "Equipes Associées"
BILAN TRIENNAL / THREE-YEAR REVIEW
|
ATTENTION : ce dossier doit obligatoirement être rédigé en anglais
Please fill in this review in ENGLISH
|
EQUIPE ASSOCIEE |
SPARS |
|
sélection / selected in year |
2007 |
|
Equipe-Projet
INRIA / Research team : METISS |
Organisme étranger partenaire / Foreign Partner Institution : EPFL |
|
Centre de recherche INRIA / Research Center :
Rennes-Bretagne Atlantique |
Pays/Country : SUISSE |
|
|
Coordinateur français/French coordinator |
Coordinateur étranger/Partner coordinator |
|
Nom,
prénom / |
GRIBONVAL Rémi |
VANDERGHEYNST Pierre |
|
Organisme d'appartenance/ Home Institution, Department,
Lab |
INRIA |
EPFL,
Laboratoire de Traitement des Signaux |
|
URL |
http://www.irisa.fr/metiss/gribonval/ |
http://ltspc89.epfl.ch/~vandergh/ |
|
|
Remi.gribonval@inria.fr |
pierre.vandergheynst@epfl.ch |
La collaboration en bref / The Collaboration in brief
|
Titre de la thématique de collaboration / Title of the collaboration theme : SPARS : efficient sparse representations for high dimensional signal processing |
|
Descriptif (environ 10 lignes) / Summary (approximately
10 lines) : The representation of a signal, image or video, as a sparse linear
combination of waveforms called elementary atoms (themselves stemming from a
large collection called dictionary) has become a key step for many tasks in
signal processing : compression, denoising, source separation... New approaches,
such as random sampling, open the way to new generations of low cost sensors able
to acquire very large yet strongly compressible data (high-resolution,
multiple sensors, multiple heterogeneous modalities, etc...), directly in the
compressed domain. Their deployment depends critically on the availability of
sparse decomposition algorithms that are both fast and efficient, in order to
reconstruct data after acquisition. The goal of this collaboration is to conceive,
develop and analyze such algorithms, validating their use for the modelling of
data, in particular in the audiovisual domain. |
BILAN
SYNTHETIQUE DE LA COLLABORATION / SYNTHESIS OF THE COLLABORATION
|
|
|
INRIA |
Partenaire(s)/ Partner |
|
Chercheurs seniors impliqués |
Senior researchers involved |
1 |
1 |
|
Post-doctorants |
Post-doctoral graduates |
0 |
4 |
|
Doctorants |
PhD students |
4 |
6 |
|
Stagiaires |
Interns |
0 |
2 |
|
Thèses en co-tutelle soutenues |
Co-supervised defended PhD |
0 |
0 |
|
Thèses en co-tutelle en cours |
Current co-supervised PhD |
1 |
1 |
|
Total des thèses soutenues |
Global defended PhD |
2 |
3 |
|
Total des thèses en cours |
Global current PhD |
2 |
3 |
|
Visites de l'équipe partenaire (hors colloques) |
Travels
to the partners (conferences not included) |
6 |
10 |
|
Nombre de Publications/Number of publications |
10 conference papers 5 journal papers (incl. 2 submitted) |
|
Quels sont, selon vous, les points forts de
cette collaboration et la valeur ajoutée de l'Equipe Associée ? |
|
Comment envisagez-vous l'avenir de cette collaboration
? (renouvellement de l'Equipe Associée, poursuite sur
fonds propres, projet européen ou autre, arrêt de la coopération...) |
BILAN SCIENTIFIQUE / SCIENTIFIC REPORT
Description de l'activité scientifique de l'équipe associée et des résultats
obtenus au cours des 3 dernières années : publications, communications,
organisation de colloques, formation, soutenances de thèse, valorisation
économique, sociale, industrielle, dépôt de brevets ... (maximum 5 pages)
Please detail the Associate Team scientific activity as well as the results
obtained in the last 3 years : publications, communications, organization of
conferences, training, defended PhD, valorization, patents filing...
Activités scientifiques.
Average-case analysis for multichannel sparse
decomposition algorithm
From the theoretical viewpoint, we focused on the robust identification
of multichannel sparse models using a wide variety of “greedy” algorithms for
joint sparse decomposition. The results have confirmed our intuition that the
typical behavior of these algorithms (for signals drawn from a known
probabilistic model) is significantly more favorable than the worst case
situation, as soon as the number of channels is large enough. Concretely, using
results on measure concentration, we have found an upper bound of the probability
of failure of these algorithms and we have proven that this probability
decreases exponentially with the number of channels, as long as the noise level
does not exceed a given threshold related to the coherence of the sparse model
being identified. These results have been published in the Journal of Fourier
Analysis and Applications [J2] and they have been presented in a number of
workshops and international conferences [P1][P2] [C1][C2][C3][C4][C5]
Dictionary learning algorithms and their experimentation
for the extraction of fibrillation signal
Joint work between the METISS Group and the LTS2 Laboratory on
shift-invariant dictionary learning have been carried out in the context of
Boris Mailhé’s PhD (co-directed), leading to an article published at the
EUSIPCO 2008 conference [P5][C8]. Further developments of this work have taken
place in cooperation with Matthieu Lemay (LTS4) for the learning of
dictionaries applied to electrocardiographic signals and were published at the
ICASSP 2009 conference [P8][C12]. A deeper exploitation of the models has been
investigated : the models have been used in order to suppress the noise from
the pathological signal prior to its analysis. Since our approach provides also
a model for the pathological component, part of the analysis can be carried out
directly in the model space, so as to reduce the volume of data and to focus on
the most relevant part of the phenomenon.
Fast quasi-orthogonal
sparse decomposition in shift-invariant dictionaries
The collaboration between the two groups (here also in the framework of Boris
Mailhé’s PhD) has lead to the definition of a fast algorithm for sparse
decomposition in shift-invariant dictionaries, which yields an approximation
quality close to that of Orthogonal Matching Pursuit for a complexity
comparable to that of Matching Pursuit. The gain in complexity is huge for the
size of signals and the types of dictionaries under consideration, dropping
from one day to 15 minute in terms of computation. A communication on this topic
was presented at ICASSP 2009 [P9][C12] and the algorithm is being integrated in
the MPTK Library, in collaboration with Dr Thomas Blumensath (Univ. Edimburgh).
Joint experiments have been carried out in cooperation with Emmanuel Ravelli
and Laurent Daudet (LAM, Univ. P; & M. Curie, Paris VI) in order to
evaluate the impact of the new algorithm on their audio codec based on MPTK. A
journal paper is in preparation.
Audiovisual source separation using sparse
representations for the audio and video components
In the framework of Anna Llagostera’s PhD, we have developed a method
for jointly separating the visual and audio structures in an audiovisual shot.
In fact, when watching an audiovisuals stimulus, human beings tend to focus
their interest on the portion of the image that moves synchronously with
incoming audio events, since human perception processes tend to correlate
intuitively the movement and the audio event. Thus, an audiovisual source can
be viewed as the reunion of the moving image segment (visual part of the
source) and the set of sounds generated by that movement (acoustic part of the
source). The task of audiovisual source separation has been achieved by
computing the time-domain consistency between the video signal and the audio
signal coming from one sensor. The efficiency of the sparse representations
used to describe the audio and video signals made it possible to calculate
empirically the correlation between the audio and video structures. Once this
correlation calculated, the active audiovisual sources in a scene were
quantified, localized and finally separated both in the audio and the video
domains.
This method was first tested on artificial audiovisual shots,
synthesized from the CUAVE database. The results were found to be of very good
quality in several respects: estimation of the number of sources, detection of
activity intervals, separation on the visual component. The separation
performance on the acoustic component was evaluated with the BSS Evaluation
Toolbox developed at INRIA, and the audio result was rated as being of good
quality too. This work was presented at the ICASSP’08 conference [P4] [C7].
In a second step, our method was exhaustively tested on a large number
of audiovisual shots, some of which showing significant complexity factors such
as the presence of musical instruments, a complex background or two speakers
with similar voices. The proposed approach yielded successful results, some of
which can be accessed on http://lts2www.epfl.ch/llagoste/BAVSSresults.htm
and they were presented in a [J3]. An extension of this work to multi-channel
audio recording was carried out in collaboration with Simon Arberet (PhD
student at IRISA) : the focus of this work was to use video information to
determine the number of active sources at a given time, and thus to aid audio
source separation methods in the underdetermined case. The approach was based
on the following steps : 1) use the (multi-channel) audio components to separate
the sources in the audio domain only, and extract from this an estimation of
the amplitude envelop for each source; 2) learn video atoms from the video
component; 3) Select those of the video atoms which are most correlated with
the audio envelop amplitude for the various sources estimated in step 1; 4)
Determine the combination of active sources from the most mobile video atoms,
when the this combination is difficult to identify in the audio-domain.
Experiments have shown that the video atoms learnt by the proposed process were
not sufficiently correlated with the audio source activity and therefor were
not usable for source separation in the case of a multi-channel instantaneous
audio mixture.
Theoretical results on
dictionary identifiability
Even though a variety of heuristic methods for dictionary learning exist in the
context of sparse representations (in particular those proposed and studied in
the framework of the Associate Team [J1]), current approaches drastically lack
of mathematical modeling and their algorithmic complexity is generally
prohibitive. We have strengthened the effort started in 2007 in exploring this
area, and we focused on the fundamental theoretical question of dictionary
identifiability. For this purpose, we have developed, in the context of Karin
Schnass’ PhD, an analytical approach which was published during the ISCCSP 2008
conference [P3][C6], which states “geometrical” conditions under which a
dictionary is ‘locally identifiable’ by L1-minimization In a second step, we
have sought to characterize the volume of training examples which are typically
needed for the dictionary to be identifiable (by L1 minimization) and we
obtained the following result : a number of training example proportional to
the dimension of the dictionary is sufficient to yield identifiability. This
property can be considered as surprising with respect to previous studies,
which hinted the need of a combinatory number of examples to guarantee
identifiability. These results were published at the EUSIPCO 2008 conference
[P6][P7][C8] and a selection of related results has been presented at the SIMAI
2008 conference [C9] and other workshops in 2009 [C10] [C11] [C13] [C14] [C15]
and submitted as a journal paper [J5].
Compressed sensing applied
to Ultra-Wide Band (UWB) signals
In collaboration with Dr Laurent Jacques (EPFL and UCL-Belgium), the SPARS
partners have defined and supervised a summer internship project (Farid Naini
Mohavedian) on sampling schemes using compressed sensing for UWB signals. More
specifically, we studied a model of signals are sparsely represented on a
shift-invariant dictionary. We have shown that it was extremely advantageous to
pre-condition the random sampling in the Fourier domain by multiplying the
signal by a wide-band sequence in the analog domain. We have also studied a
simplified scenario which enables a hardware implementation of our technique
and we checked that the performance was not affected by this simplification. Our
approach could be applied in UWB communication but also for sensor design in
the field of life sciences. Our results were published at the ICASSP 2009
conference [P10][C12].
Wavelets on graphs
There are many problems where data is collected through a graph structure:
scattered or non-uniform sampling, sensor networks, data on sampled manifolds
or even social networks or databases. Motivated by the wealth of new potential
applications of sparse representations to these problems, the partners set out
a program to generalize wavelets on graphs. More precisely, we have introduced
a new notion of wavelet transform for data defined on the vertices of an
undirected graph. Our construction uses the spectral theory of the graph
laplacian as a generalization of the classical Fourier transform. The basic
ingredient of wavelets, multi-resolution, is defined in the spectral domain via
operator-valued functions that can be naturally dilated. These in turn define
wavelets by acting on impulses localized at any vertex. We have analyzed the
localization of these wavelets in the vertex domain and showed that our multi-resolution
produces functions that are indeed concentrated at will around a specified
vertex. Our theory allowed us to construct an equivalent of the continuous
wavelet transform but also discrete wavelet frames.
Computing the spectral decomposition can
however be numerically expensive for large graphs. We have shown that, by
approximating the spectrum of the wavelet generating operator with polynomial
expansions, applying the forward wavelet transform and its transpose can be
approximated through iterated applications of the graph Laplacian. Since in
many cases the graph Laplacian is sparse, this results in a very fast
algorithm. Our implementation also uses recurrence relations for computing
polynomial expansions, which results in even faster algorithms. Finally, we
have proved how numerical errors are precisely controlled by the properties of
the desired spectral graph wavelets. Our algorithms have been implemented in a
Matlab toolbox that will be released in parallel to the main theoretical article
[J4]. We also plan to include this toolbox in the SMALL project numerical
platform.
We now foresee many applications. On one hand
we will use non-local graph wavelets constructed from the set of patches in an
image (or even an audio signal) to perform de-noising or in general restoration.
An interesting aspect in this case, would be to understand how wavelets
estimated from corrupted signals deviate from clean wavelets. In a totally
different direction, we will also explore the applications of spectral graph
wavelets constructed from brain connectivity graphs obtained from whole brain
tractography. Our preliminary results show that graph wavelets yield a
representation that is very well adapted to how the information flows in the
brain along neuronal structures.
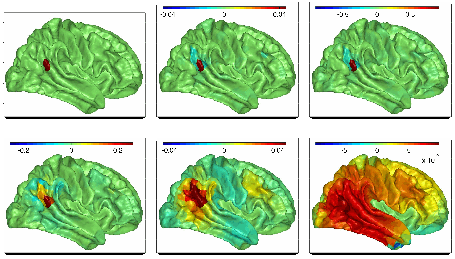
A set of graph
wavelets constructed from brain connectivity data. As the scale parameter gets
higher, the wavelet grows along neuronal pathways connecting brain areas.
Publications conjointes
Congrès avec actes
[P1] R. Gribonval, B.
Mailhé, H. Rauhut, K. Schnass, P. Vandergheynst. Average case analysis of multichannel thresholding. Proc. IEEE
ICASSP’07.
[P2] R. Gribonval, B. Mailhé,
H. Rauhut, K. Schnass & P. Vandergheynst. Average case of multichannel sparse approximations using p-thresholding.
Proc. SPIE Symposium on Optical Engineering and its Applications, San Diego,
Sept. 2007.
[P3] R. Gribonval and K.
Schnass, Some Recovery Conditions for Basis Learning by L1-Minimization,
Proc. IEEE International Symposium on Communications, Control and Signal
Processing (ISCCSP 2008), Malta.
[P4] A. Llagostera
Casanovas, G. Monaci, P. Vandergheynst and R. Gribonval, Blind Audiovisual
Separation based on Redundant Representations, Proc. of IEEE International
Conference on Acoustics, Speech and Signal Processing, 2008.
[P5] B. Mailhé, S. Lesage,
R. Gribonval, P. Vandergheynst, F. Bimbot. Shift-invariant dictionary
learning for sparse representations: extending K-SVD, EUSIPCO'08.
[P6] R. Gribonval and K.
Schnass, Dictionary Identifiability from Few Training Samples, Proc.
EUSIPCO'08, 2008.
[P7] R. Gribonval, K.
Schnass. Basis identification from Random
Sparse Samples. Proc. SPARS’09 (2009).
[P8] B. Mailhé, M. Lemay,
P. Vandergheynst, J.-M. Vesin, R. Gribonval, F. Bimbot, Dictionary learning
for the sparse modelling of atrial fibrillation in ECG signals. Proc. IEEE-ICASSP'09.
[P9] B. Mailhé, R.
Gribonval, P. Vandergheynst, F. Bimbot, A LOw Complexity Orthogonal Matching
Pursuit algorithm for sparse signal approximation with shift-invariant
dictionaries, Proc. IEEE-ICASSP'09.
[P10] F.M. Naini, R. Gribonval, L. Jacques and P. Vandergheynst. Compressive Sampling of Pulse Trains : Spread the Spectrum ! Proc. IEEE-ICASSP'09.
Journaux à comité de lecture
[J1] G. Monaci, P. Jost, P. Vandergheynst, B. Mailhé, S. Lesage, R.
Gribonval. Learning Multi-Modal Dictionaries. IEEE Trans. on Image Processing,
Vol. 16, n° 9, pp. 2272-2283, Sept. 2007.
[J2] R. Gribonval, H.
Rauhut, K. Schnass and P. Vandergheynst, Atoms
of all channels, unite! Average case analysis of multi-channel sparse recovery
using greedy algorithms, J. Fourier Analysis and Applications, 14 (2008),
pp.655-687.
[J3] A. Llagostera
Casanovas, G. Monaci, P. Vandergheynst and R. Gribonval. Sparsity and Synchrony in Blind Audio-Visual Source
Separation. To appear in IEEE Trans. on Image Processing.
[J4] D. K. Hammond, R.
Gribonval, P. Vandergheynst. Wavelets on
Graph via Spectral Theory. Submitted to Applied and Computational Harmonic
Analysis.
[J5] K. Schnass and R.
Gribonval. Dictionary Identification -
Sparse Matrix-Factorisation via \$\ell_1\$-Minimisation. Submitted to IEEE Transactions
on Information Theory.
Communications
[C1] ICASSP 2007, Hawaii, April 2007
[C2] AMS von Neumann
Symposium on Sparse Representation and High Dimensional Geometry, Snowbird,
Utah, July 2007.
[C3] Rencontre sur le Traitement Mathématique des Images, Centre International de rencontres mathématiques, Marseilles, Sept. 2007.
[C4] SPIE, San Diego, Sept.
2007
[C5] CAMSAP, Virgin
Islands, Dec. 2007
[C6] ISCCSP 2008, Malte,
March 2008
[C7] ICASSP 2008, Las
Vegas, April 2008
[C8] EUSIPCO 2008,
Lausanne, August 2008
[C9] SIMAI 2008, Rome,
September 2008
[C10] Workshop
"sparsity and large inverse problems" Cambridge, December 2008
[C11] SPARS 2009, St-Malo,
April 2009
[C12] ICASSP 2009, Taipeh,
April 2009
[C13] Solvay Workshop on
"sparsity, learning and computation", Solvay Institute, Brussels,
2009
[C14] EPSRC Capstone Conference,
Warwick, UK, July 2009
[C15] Workshop "dictionary of
atoms : new trends in advanced brain signal processing", Montreal, Canada,
2009
Organisations de rencontres / colloques
One-day workshop at
IRISA on “sparse representations of signals and images” was
organized on October 24th 2007 in conjunction with Remi Gribonval
HDR defense
One-day meeting on
« Sparsity » in the framework of the ISIS working group (April 17th,
2008) co-organised by Rémi Gribonval and Laure Blanc-Feraud (Ariana Group,
I3S, Nice). This event took place in Telecom Paris Tech and gathered more than
100 participants.
One-day meeting
coorganised with the TEXMEX and TEMICS groups at IRISA, on Mai 29th 2008. The topic
of the day was “Images, databases, random projections and sparsity”. Pierre
Vandergheynst (EPFL), Laurent Amsaleg (IRISA/TEXMEX) and Joaquin Zepeda
(IRISA/TEMICS) gave presentations followed by discussions on the links between
sparse representations, database indexing and random projections.
SPARS’09 Workshop,
St-Malo, France, April 6-9, 2009
The SPARS'09
workshop was held at the beginning of April 2009 in St-Malo. It gathered about 90
participants. Beside 28 oral communications and 28 poster presentations, 4
invited talks were given by Anna Gilbert (Univ. Michigan, USA), Justin Romberg
(Georgia Tech., USA), Mark Plumbley (Queen Mary Univ, London, UK) and Ron de
Vore (Member of the USA Academy of Science, Texas A&M Univ., USA). These
invited talks covered a number of selected topics such as deterministic
and probabilistic dimensionality reduction in large spaces, compressed sensing,
sparse approaches for audio information representation and large-scale process
modeling. Rémi Gribonval was the General Chairman of the workshop. Pierre
Vandergheynst was a member of the Programme Committee.
Projet européen FET-Open (FP7) SMALL
The SMALL (Sparse Models,
Algorithms and Learning for Large-scale data) project has been selected in the Fall
2008 in the framework of the European FET-Open programme, and started in the
Spring 2009. Beside INRIA (coordinator, C/° Rémi Gribonval) and EPFL (C/° Pierre
Vandergheynst), the partners are :
Centre for Digital Music, Queen Mary University of London (C/° Mark Plumbley),
University of Edinburgh, UK, (C/° Mike Davies) and The Technion, Israël, (C/°
Miki Elad). The objective of the SMALL project is to develop a new foundational
framework for processing signals, using adaptive sparse structured
representations. SMALL will explore new generations of provably good methods to
obtain inherently data-driven sparse models, able to cope with large-scale and
complicated data much beyond state-of-the-art sparse signal modeling. The
project will develop a radically new foundational theoretical framework for the
dictionary-learning problem, and scalable algorithms for the training of structured
dictionaries
© INRIA - mise à jour le 08/07/2009