Du fait de sa popularité, les processeurs de la série 80x86 ont été les processeurs les plus largement copiés, du NEC V20, clone du 8086, aux clones d'AMD et de Cyrix des processeurs 80386 et 80486, et maintenant du Pentium.
Nous avons décidé d'intégrer dans l'étude consacrée aux processeurs
Intel les compatibles Pentium, car il est sûr que ces processeurs
joueront un rôle non négligeable sur le marché. Ainsi, Compaq a
récemment annoncé qu'il utiliserait le Nx586 de Nexgen![]() pour certains de ses
modèles. AMD, qui fournit déjà Hewlett-Packard en 486, pourrait
bien se voir également sélectionné pour son futur K5.
pour certains de ses
modèles. AMD, qui fournit déjà Hewlett-Packard en 486, pourrait
bien se voir également sélectionné pour son futur K5.
Par ailleurs, l'étude de ces compatibles est particulièrement intéressante dans la mesure où elle fait ressortir les défauts du jeu d'instructions et illustre les diverses solutions mises en oeuvre pour y remédier.
Le processeur M1 de Cyrix a été annoncé à la fin de l'année 1993. Il devait être commercialisé au deuxième semestre 1994, mais finalement une version simplifiée de ce composant, le M1sc a vu le jour en juillet 1995. Ce processeur fait appel à des techniques avancées d'architecture telles que prédiction de branchement, exécution spéculative et dans le désordre et renommage de registres.
L'un des gros problèmes de l'architecture Intel est le faible nombre de registres : huit, par rapport aux 32 registres classiques d'une architecture RISC. Ceci a pour conséquence un nombre important de transferts entre la mémoire et les registres, les opérandes pouvant être directement accédées en mémoire puisque, comme on l'a vu, le jeu d'instructions supporte ce type d'opérations. Cette situation tend à diminuer les performances de deux manières :
Une solution classique à ce second problème est de mettre en oeuvre un mécanisme de renommage de registres. C'est la solution choisie par Cyrix qui implémente 32 registres physiques pour les huit registres logiques vus par le programmeur.
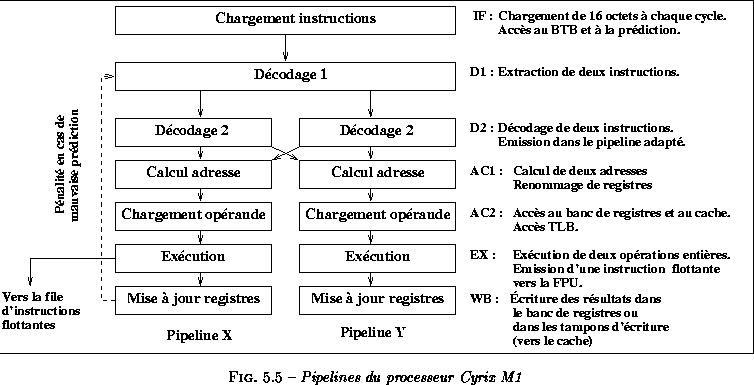
L'efficacité du design du M1 se ressent également au niveau des
vraies dépendances (RAW). La figure ![]() schématise les deux pipelines d'exécution implémentés sur ce
processeur. Les pipelines incluent des étages séparés pour la lecture
des données, la phase de calcul et enfin l'étape de mise à jour de la
mémoire. Dans le cas d'une séquence d'opérations dépendantes (par
exemple :MOV DX, [mem] ; ADD AX, DX) les mécanismes de bypass mis en oeuvre entre les deux pipelines permettent
d'exécuter ces instructions en parallèle. Dans la mesure où, sur le
Pentium, l'étage de lecture des opérandes et l'étage de calcul arithmétique
sont concurrents, ces deux opérations sont exécutées séquentiellement
schématise les deux pipelines d'exécution implémentés sur ce
processeur. Les pipelines incluent des étages séparés pour la lecture
des données, la phase de calcul et enfin l'étape de mise à jour de la
mémoire. Dans le cas d'une séquence d'opérations dépendantes (par
exemple :MOV DX, [mem] ; ADD AX, DX) les mécanismes de bypass mis en oeuvre entre les deux pipelines permettent
d'exécuter ces instructions en parallèle. Dans la mesure où, sur le
Pentium, l'étage de lecture des opérandes et l'étage de calcul arithmétique
sont concurrents, ces deux opérations sont exécutées séquentiellement
![]() . Par ailleurs, ces mécanismes
jouent également un rôle au niveau du couplage des instructions plus
performant sur ce processeur.
. Par ailleurs, ces mécanismes
jouent également un rôle au niveau du couplage des instructions plus
performant sur ce processeur.
Les deux pipelines ne sont pas symétriques. Le << pipeline X >> est le seul à gérer les branchements ainsi que les instructions flottantes.
Le pipeline, décrit figure ![]() est particulièrement
long par rapport aux cinq étages classiques des processeurs RISC ou du
Pentium. La technique du superpipeline utilisée est à rapprocher du
design des processeurs Alpha et MIPS R4000. Le problème classique de
ce type de pipeline est celui due à une mauvaise prédiction de
branchement. Pour y remédier, le M1 utilise un BTB (Branch Target
Buffer) associatif par ensemble à quatre voies d'une capacité de 256
entrées (idem que le Pentium). La prédiction de branchement utilisée
est identique à celle du Pentium (prédiction à deux bits). Le
processeur de Cyrix implémente également une pile d'adresses de retour
de huit entrées. Ce design, similaire à celui de processeurs hautes
performances tels que DEC ou MIPS, devrait améliorer le taux de bonnes
prédictions de 5%par rapport à celui du Pentium. Par ailleurs, le
tampon de préchargement a la capacité de maintenir jusqu'à quatre
flots d'instructions prédits ainsi que les quatre flots d'instructions
séquentiels associés. Aussi, même en cas de mauvaises prédictions, ce
tampon peut fournir les instructions, éliminant ainsi un cycle de
délai dû à l'adressage du cache d'instructions.
est particulièrement
long par rapport aux cinq étages classiques des processeurs RISC ou du
Pentium. La technique du superpipeline utilisée est à rapprocher du
design des processeurs Alpha et MIPS R4000. Le problème classique de
ce type de pipeline est celui due à une mauvaise prédiction de
branchement. Pour y remédier, le M1 utilise un BTB (Branch Target
Buffer) associatif par ensemble à quatre voies d'une capacité de 256
entrées (idem que le Pentium). La prédiction de branchement utilisée
est identique à celle du Pentium (prédiction à deux bits). Le
processeur de Cyrix implémente également une pile d'adresses de retour
de huit entrées. Ce design, similaire à celui de processeurs hautes
performances tels que DEC ou MIPS, devrait améliorer le taux de bonnes
prédictions de 5%par rapport à celui du Pentium. Par ailleurs, le
tampon de préchargement a la capacité de maintenir jusqu'à quatre
flots d'instructions prédits ainsi que les quatre flots d'instructions
séquentiels associés. Aussi, même en cas de mauvaises prédictions, ce
tampon peut fournir les instructions, éliminant ainsi un cycle de
délai dû à l'adressage du cache d'instructions.
L'unité flottante n'est pas pipelinée. Les instructions sont envoyées vers
une file d'instructions de quatre entrées. Une gestion précise des
exceptions est maintenue.
Le Cyrix M1 permet l'exécution des instructions dans le désordre. Si un défaut
de cache survient dans l'un des pipelines, le deuxième pipeline permet de
poursuivre l'exécution du flot d'instructions. Cependant, la complexité
de la gestion des dépendances de données, ainsi que la nécessité de
maintenir des exceptions précises ont limité l'exécution dans le désordre
des instructions à une seule dépendance.
Le bypass de la mémoire est également une technique qui permet de réduire les effets du nombre limité de registres sur les processeurs xxx86. Comme la plupart des processeurs, le M1 fournit directement la donnée qui a été calculée (ou lue) au cycle précédent à l'unité fonctionnelle, supprimant ainsi le passage par le banc de registres. Le design du M1 va au-delà en permettant le bypass même si la donnée est écrite en mémoire plutôt que dans le banc de registres. Un tel mécanisme est particulièrement utile sur des processeurs tels que les xxx86 où le faible nombre de registres impose au compilateur de conserver des variables en mémoire. L'exemple suivant illustre l'efficacité d'un tel mécanisme :
Dans cet exemple, CX est ajouté à la valeur contenue à l'adresse mem, puis le résultat est soustrait à DX. L'architecture du M1 détecte que l'adresse fournie par mem est la même pour les deux instructions et bypass le résultat du premier calcul directement à l'instruction SUB. Sur d'autres processeurs, y compris le Pentium, il est nécessaire d'attendre la mise à jour de la mémoire avant que la seconde instruction puisse commencer à lire son opérande. Cette séquence prend alors quatre cycles. À noter que ce mécanisme peut être relativement compliqué, car si il est facile de comparer des descripteurs de registres sur trois bits pour détecter une correspondance, le bypass de la mémoire, nécessite quant à lui la comparaison de toute l'adresse.
Cyrix a fait le choix d'un cache unifié de 16 Ko (même capacité que les deux caches du Pentium). Ce choix présente généralement un meilleur taux de succès qu'un cache séparé de taille totale égale mais pose le problème de l'accès concurrent aux instructions et aux données. Aussi, Cyrix a ajouté à ce design un petit cache d'instructions totalement associatif de 256 octets pour limiter ce type de conflit. Par ailleurs, comme le Pentium, il utilise un double ports permettant deux lecture/écriture à chaque cycle. Pour gérer les accès en cas de conflits, Cyrix utilise un algorithme qui alloue la plus haute priorité au chargement d'instructions puis aux lectures, puis aux écritures qui sont temporairement conservées dans des tampons en attente. Le cache lui-même n'est pas réellement un vrai double-port, mais utilise une structure de bancs.
De même que dans le cas du Pentium, cette structure de bancs permet deux accès par cycle tant que les accès utilisent des bancs différents. Le cache de données du Pentium utilise huit bancs entrelacés sur des frontières de 32 bits. Le M1 utilise 16 bancs de 16 bits de large réduisant ainsi légèrement les conflits. Ceci devrait se ressentir sur les codes accédant des données de huit ou seize bits.
Le TLB unifié est quant à lui réellement double-ports et permet de générer deux adresses physiques à chaque cycle. Il a une capacité de 128 entrées (à comparer aux 64+32 du Pentium). Le cache unifié est virtuellement adressé permettant ainsi l'adressage en parallèle du cache et la traduction des adresses. Par ailleurs, pour éviter les problèmes liés aux rejets << intempestifs >>, le M1 inclut un tampon de huit entrées destinées à recevoir les victimes vidées du TLB principal.
Conçu en technologie CMOS à 0.65 m avec trois couches de métal,
ce processeur fut initialement prévu à la fréquence de 100 MHz. De
récentes annonces prévoient un passage à une technologie à
0.5
m pour une fréquence de 133 MHz (disponible au cours du premier
trimestre 1996). Produit par IBM et SGS-Thomson, la
production devrait atteindre 10 000 processeurs par mois d'ici la fin
du second semestre 1995 par rapport aux deux millions de Pentium
produit durant la même période, laissant le M1 avec moins de 1%du
marché.
Le M1 de Cyrix inclut 3 millions de transistors. Ce processeur devrait permettre de concurrencer de manière efficace le Pentium d'Intel. Les techniques avancées mises en oeuvre permettront des performances de 40%supérieures à celles du processeur Pentium séquencé à la même fréquence (selon Cyrix).
Annoncé fin 1994, ce processeur vise au même titre que le M1 de Cyrix,
le marché des Pentium. Il constitue le premier composant d'AMD
entièrement développé à partir d'un coeur AMD. En développant ainsi
sa propre architecture, AMD tente de se mettre à l'abri de toutes
poursuites juridiques d'Intel. Le premier composant de cette série
porte le nom de K5.
Le coeur de ce processeur est basé sur une architecture
superscalaire permettant l'émission de quatre instructions à chaque
cycle, une exécution spéculative et dans le désordre, ainsi que le
renommage de registres. Cette architecture va au-delà de celle du
Pentium et du M1 en utilisant une architecture totalement découplée
permettant un plus haut taux d'exécution d'instructions
superscalaires.
Le K5 d'AMD propose une solution différente de celle apportée par Cyrix pour résoudre les problèmes de performances de l'architecture Intel.
Du fait de la taille variable des instructions xxx86 (jusqu'à
15 octets), il est particulièrement délicat de décoder plusieurs de
ces instructions en parallèle dans la mesure où la prochaine
instruction ne peut pas être décodée tant que la longueur de
l'instruction qui la précède est inconnue (le Pentium montre que cela
est possible mais ne décode que deux instructions à la fois).
Les
concepteurs d'AMD ont évité ce problème en pré-décodant les
instructions au moment de leur chargement depuis la mémoire dans le cache
(d'une capacité de 16 Ko). L'information de pré-décodage résout ainsi
le problème de la taille variable des instructions xxx86. Le
pré-décodage ajoute cinq bits à chaque octets. Ces bits indiquent si
l'octet est le début ou la fin d'une instruction xxx86, le nombre de
micro-instructions nécessaires pour l'émuler, ainsi que la
localisation des codes opérations et des préfixes. Bien que ces bits
de pré-décodage augmentent la taille du cache d'environ 50%, ils
réduisent de manière non négligeable la complexité du mécanisme
d'émission superscalaire d'instructions.
Après avoir été chargées dans le cache, ces instructions sont converties en une ou plusieurs micro-instructions, appelées selon la terminologie utilisée par AMD, << opérations RISC >>, ou ROPs (pour RISC Operations). Les instructions xxx86 sont extraites du cache au rythme de 16 octets à chaque cycle (plus les 80 bits de pré-décodage) pour être converties en ROPs. Jusqu'à quatre ROPs peuvent être émises à chaque cycle.
Les ROPS ne sont pas des instructions RISC au sens traditionnel du terme mais en partagent cependant deux caractéristiques principales :
À la différence d'autres machines superscalaires telles que le Pentium, il n'y a pas de règles de groupement d'instructions pour les émettre. Même les frontières d'instructions xxx86 ne limitent pas l'émission des ROPs. Exécuter des codes non recompilés spécifiquement, est l'une des gageures du marché xxx86. Le K5 évite ainsi de recourir à un besoin spécifique d'optimisation du compilateur.
Les instructions sont chargées à partir du cache dans une file de 16 octets. La logique de chargement essaye de maintenir cette file pleine, en suivant si nécessaire les branchements. Au fur et à mesure que ces instructions sont consommées, de nouvelles instructions sont ajoutées à partir du cache. Jusqu'à quatre instructions peuvent être extraites de cette file. Dans la mesure où ces instructions ont déjà été pré-décodées, il est relativement simple de localiser les frontières d'instructions et d'isoler celles susceptibles de fournir quatre ROPS.
Les quatre convertisseurs de ROPs sont identiques et peuvent gérer n'importe quelles instructions. La plupart des instructions xxx86 sont traduites directement en ROPs. Les instructions complexes sont converties en de multiples ROPs et le flot d'instructions est réarrangé pour qu'il conserve sa cohérence.
Toute instruction pouvant être traduite en une, deux, voire trois ROPs est gérée entièrement par matériel. Pour des instructions plus complexes, telles que des manipulations de chaînes de caractères, qui nécessitent quatre ROPs ou plus, des << séquences ROP >> (similaire à du microcode) de la MROM sont utilisées. La MROM peut émettre quatre ROPs par cycle.
Une fois les convertisseurs d'instructions xxx86 en ROP passés, le coeur du K5 est similaire à celui d'un processeur RISC classique à l'exception de certaines caractéristiques destinées à supporter le jeu d'instructions xxx86 (notamment l'ajout de logique aux deux unités de lecture/écriture comme support aux modes d'adressage complexes xxx86).
On peut remarquer que l'émission de quatre instructions par cycle est basée sur des instructions ROPs. Si chaque instruction xxx86 ne requiert qu'une ROP, alors quatre instructions xxx86 pourront être émises à ce cycle. En moyenne, les codes xxx86 16-bit, produisent 1.9 ROPs par instruction et les codes 32-bit, 1.3 ROP par instruction. Aussi, en terme d'émission d'instructions xxx86, il faut compter en moyenne deux instructions pour du code 16-bits et trois pour du code 32-bit.
Les instructions ROP sont émises vers des stations de réservation où
elles attendent la disponibilité de leurs opérandes. Chaque unité a
deux stations de réservation à l'exception de la FPU qui n'en possède
qu'une. Le mécanisme d'émission est bloqué dès qu'une des stations de
réservation est pleine.
Le K5 a six unités d'exécution :
L'unité flottante n'inclut pas la traditionnelle pile de registres flottants des processeurs xxx86. Cette pile est en fait émulée dans le banc de registres généraux à travers un mécanisme spécifique de renommage.
Huit bus d'opérandes permettent d'alimenter quatre unités d'exécution à chaque cycle. Cinq bus servent aux résultats. Chaque bus a une largeur de 41 bits pour supporter le transfert de données flottantes (dans ce cas deux bus sont utilisés en parallèle). Le banc de registres a une capacité de 40 entrées. Il contient les données destinées à la pile flottante ainsi que des registres temporaires (renommage) utilisés pour passer les données entre les ROPs.
Un tampon de réordonnancement de 16 entrées récupère les instructions exécutées spéculativement. Tous les résultats sont d'abord inscrits dans ce tampon, le banc de registres étant mis à jour au moment où on a la certitude que l'instruction devait bien être exécutée. Les opérandes peuvent être chargés soit à partir du banc de registres, soit à partir de ce tampon. Le mécanisme de renommage est mis en oeuvre au sein même de ce tampon de réordonnancement qui facilite par ailleurs la prédiction des branchements ainsi que la gestion précise des exceptions.
Le pipeline utilisé par ce processeur a six étages, mais seul cinq comptent au niveau des performances puisque le sixième (le tampon de réordonnancement) n'affecte pas les performances (les opérandes pouvant y être lus).
Comparé aux cinq étages du Pentium, ce processeur utilise un étage supplémentaire pour la conversion des instructions xxx86 en ROPs. Le K5 compense ce cycle supplémentaire en combinant la génération de l'adresse dans le même étage que l'accès au cache.
Les branchements sont prédits à partir d'un schéma simple de
prédiction à un bit associé à chaque ligne de cache. Ce bit
d'historique reflète la dernière direction prise lors de l'exécution
du branchement. Dans le cas d'une boucle cependant, un branchement
arrière prédit pris ne changera pas ce bit si la prédiction s'avère
fausse. L'entrée de prédiction pour chaque ligne de cache inclut un
pointeur vers l'instruction cible, avec son index de cache et le
déplacement dans la ligne. Ce pointeur permet de suivre un branchement sans
cycle de pénalité. La pénalité maximale pour une mauvaise prédiction
est de trois cycles (ou 12 ROPs potentielles).
Ce schéma permet d'associer une prédiction à chacune des 1024 lignes
du cache (soit quatre fois la capacité de prédiction du Pentium). AMD
pense que cette approche est aussi efficace que celle du
Pentium. L'exactitude de la prédiction est moins bonne, mais
l'information de prédiction sauvée concerne beaucoup plus de
branchements. On peut cependant remarquer, que bien que cette méthode
fournisse une prédiction dynamique à un coût minimal, elle a des
inconvénients. Certains groupes d'instructions peuvent ne pas contenir
de branchements, gaspillant ainsi l'entrée. D'autres au contraire,
peuvent avoir de multiples branchements créant ainsi des interférences
au moment ou l'historique d'un branchement réécrit celui d'un
branchement du même groupe.
Les deux unités de lecture/écriture permettent deux accès à chaque cycle (tant que les bancs adressés sont différents ; le cache de données est divisé en quatre bancs) vers les 8 Ko du cache de données. Deux unités sont incluses du fait de l'incidence des lectures et écritures dans le flot d'instructions ROP, conséquence de la pauvreté en registres de l'architecture xxx86.
Les deux caches primaires sont virtuellement adressés et testés afin d'éviter la traduction de l'adresse. Un TLB unifié de 128 entrées fournit cependant les adresses physiques vers le sous-système mémoire.
Réalisé en technologie CMOS à 0.5 m et trois couches de métal, ce
processeur utilise 4.3 millions de transistors (à comparer aux 3.3 millions
du Pentium). AMD prévoit de passer à une production à 0.35
m (pour
une fréquence de 133 MHz) d'ici 1996.
Les simulations menées par AMD montrent qu'à la même fréquence, le K5 devrait être au moins 30%plus rapide que le Pentium (sur les codes entiers), les performances flottantes devant être moindres mais toujours comparables.