Développé par la société Hal Computer Systems, ce processeur a été annoncé en mars 1995 et devrait être commercialisé d'ici la fin de cette année. Il vise le marché des stations de travail haut de gamme et des serveurs et se place donc sur le même plan que l'UltraSPARC avec des performances comparables : 256 SPECint92 et 330 SPECfp92.
Créé en 1990 à l'initiative de Andrew Heller![]() , Hal a rejoint le
groupe Fujitsu début 1991.
Cette fusion s'inscrit dans une politique globale de la part de Fujitsu d'être présent sur le marché des processeurs milieu et haut de
gamme. Effectivement, déjà propriétaire de Ross Technology, Fujitsu développe l'HyperSPARC. Le Sparc64 lui permet d'occuper le marché haut de
gamme.
, Hal a rejoint le
groupe Fujitsu début 1991.
Cette fusion s'inscrit dans une politique globale de la part de Fujitsu d'être présent sur le marché des processeurs milieu et haut de
gamme. Effectivement, déjà propriétaire de Ross Technology, Fujitsu développe l'HyperSPARC. Le Sparc64 lui permet d'occuper le marché haut de
gamme.
Ce processeur ne devrait pas être distribué sur l'ensemble du marché. Celui-ci sera plutôt utilisé dans un premier temps pour des besoins internes, au sein des systèmes commercialisés par Fujitsu ainsi que dans les deux autres compagnies où elle intervient : Amdhal et ICL.
Ce processeur met en oeuvre une architecture découplée conforme à la norme SPARC-V9. Des caractéristiques originales de sa mise en oeuvre prédestinent ce processeur aux applications hautes performances utilisant de vastes ensembles de travail ou une grande fiabilité (cas des serveurs d'entreprises).
Le Sparc64 est une implémentation multicomposant (conditionnement MCM). Il est constitué de deux composants logiques et de quatre composants mémoire responsables des fonctionnalités suivantes :
L'accès aux deux caches externes est pipeliné et a une latence de trois cycles. Ces caches sont tous deux virtuellement adressés et testés. Chaque ligne de cache (d'une capacité de 128 octets) se répartit sur les deux composants créant ainsi deux bancs par cache. Chacun des bancs peut être adressé individuellement permettant ainsi de servir deux requêtes par cycle. Les caches sont non bloquants et peuvent fonctionner avec deux défauts de cache en attente. Bien que les deux caches soient identiques, leur utilisation est cependant différente.
Les 128 Ko de cache d'instructions constituent un cache secondaire après
les 4 Ko mis en oeuvre sur l'unité centrale![]() . Ce plus petit cache
a une latence de un cycle. Les deux caches sont accédés à chaque
cycle. Le but du cache primaire est de répondre rapidement (en cas
d'urgence, cas d'une mauvaise prédiction de branchement par exemple),
tandis que le cache secondaire répond plus lentement, mais grâce à
son taux de défaut peu élevé, permet de soutenir un débit effectif
important. Cette approche est valide dès lors que le débit en
instructions du cache secondaire est largement supérieur à la demande
réelle du processeur.
. Ce plus petit cache
a une latence de un cycle. Les deux caches sont accédés à chaque
cycle. Le but du cache primaire est de répondre rapidement (en cas
d'urgence, cas d'une mauvaise prédiction de branchement par exemple),
tandis que le cache secondaire répond plus lentement, mais grâce à
son taux de défaut peu élevé, permet de soutenir un débit effectif
important. Cette approche est valide dès lors que le débit en
instructions du cache secondaire est largement supérieur à la demande
réelle du processeur.
L'unité de chargement mise en oeuvre sur le Sparc64 est relativement complexe. Elle fournit à l'unité de séquencement quatre instructions à chaque cycle.
L'unité de séquencement lit les opérandes sources, renomme les registres destinations et émet jusqu'à quatre instructions à chaque cycle vers les stations de réservation associées à chaque unité d'exécution. Cette unité peut gérer jusqu'à deux opérations flottantes, deux instructions de lecture/écriture et un branchement. Elle peut également traiter jusqu'à quatre opérations entières si deux au moins restent des calculs simples (pas de décalage ni de multiplication et division).
Le Sparc64 est le premier processeur de cette architecture à mettre en
oeuvre un renommage de registres (gestion rendue plus complexe du
fait des fenêtres). Il implémente pour cela 38 registres entiers et 24
registres flottants supplémentaires. Le renommage est une technique
particulièrement efficace pour supprimer les fausses dépendances,
situation fréquente dans les processeurs exécutant les instructions
dans le désordre. Pour suivre la trace de l'exécution des
instructions, une étiquette de six bits est assignée à chaque
instructions. Cette mise en oeuvre diffère du traditionnel tampon
de réordonnancement utilisé sur la plupart des microprocesseurs (AMD
K5, PowerPC 620, UltraSPARC). La largeur de l'étiquette permet d'avoir
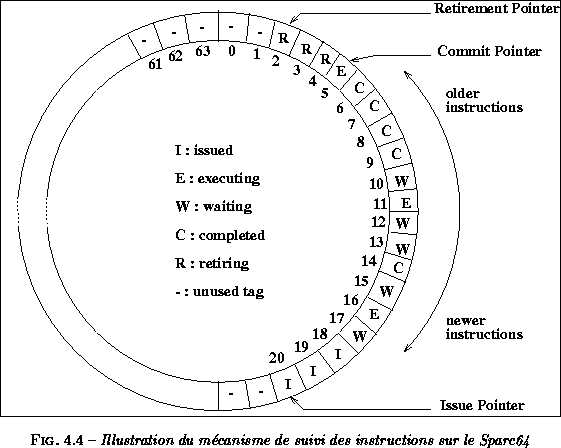
jusqu'à 64 instructions actives en même temps. La figure
![]() explicite ce mécanisme. Sur cette
figure, les instructions actives les plus anciennes sont prêtes à être
retirées de la même manière que les instructions qui les précédaient.
L'instruction (5) est toujours en cours d'exécution, empêchant
les instructions (6-9) d'être retirées bien que leur exécution
soit achevée. Les instructions suivantes sont dans diverses phases
d'exécution, les instructions les plus récentes (18-20) sont en
cours d'émission. Sur cet exemple seules 19 instructions sont
actives. Trois pointeurs sont utilisés pour contrôler ce procédé :
explicite ce mécanisme. Sur cette
figure, les instructions actives les plus anciennes sont prêtes à être
retirées de la même manière que les instructions qui les précédaient.
L'instruction (5) est toujours en cours d'exécution, empêchant
les instructions (6-9) d'être retirées bien que leur exécution
soit achevée. Les instructions suivantes sont dans diverses phases
d'exécution, les instructions les plus récentes (18-20) sont en
cours d'émission. Sur cet exemple seules 19 instructions sont
actives. Trois pointeurs sont utilisés pour contrôler ce procédé :
Cette méthode est plus simple que le tampon de réordonnancement où toutes les instructions actives sont sauvegardées avec leur résultat dans un vaste fichiers de registres mais nécessite de disposer d'un mécanisme de renommage pour conserver les résultats des instructions exécutées de manière spéculative.
Après leur renommage, les instructions sont émises dans l'une des quatre stations de réservation ou dans l'unité de branchement (architecture découplée). Ces stations ont des capacités variables : huit entrées pour les unités entière, flottante et de calcul d'adresses, 12 entrées pour les opérations d'accès à la mémoire. Chacune de ces stations peut recevoir deux instructions par cycle. Les instructions attendent au sein de ces tampons la disponibilité de leurs opérandes avant d'être émises vers les unités d'exécution. Si plus d'une instruction peut être émise, la plus ancienne est alors choisie.
En ce qui concerne les instructions entières, deux opérations peuvent être émises par cycle. Deux unités d'exécution non symétriques sont implémentées (seule une ALU dispose d'un opérateur de multiplication et division). Deux calculs d'adresse peuvent également être émis vers deux autres unités d'exécution. Ces deux unités peuvent également accepter des opérations entières. Par conséquent jusqu'à quatre opérations entières peuvent être exécutées à chaque cycle.
Deux instructions flottantes peuvent être émises vers une unité flottante générale ou vers une unité de division flottante. L'unité flottante comprend un pipeline de quatre étages de multiplication-addition.
Pour répondre aux exigences de cette architecture, le banc de registres
entiers dispose de dix ports de lecture et de quatre ports d'écriture. Le
banc de registres flottants est quant à lui équipé de six ports de lecture
et trois ports d'écriture. Un tel nombre de ports est difficilement
compatible avec les spécifications de l'architecture SPARC qui impose un
nombre de registres important. L'UltraSPARC évite ce problème grâce à une méthode de
compression du banc de registres (banc de registres à trois dimensions),
mais Hal na pas pu réutiliser cette technique. Aussi, seules quatre
fenêtres de registres sont mises en oeuvre au lieu des sept ou huit des
processeurs SPARC classiques. La taille du banc de registres reste ainsi
acceptable, la conséquence étant un transfert de données plus important avec
la mémoire en cas de débordement de fenêtres de registres (après
quatre appels de procédures emboîtées).
La gestion des branchements est toujours délicate sur une architecture
découplée superscalaire où une mauvaise prédiction peut causer l'abandon
d'un nombre important d'instructions.
Le Sparc64 implémente pour cela une table d'historique de branchement (BHT) de 1024 entrées basée sur une prédiction à deux bits (algorithme de Smith). Au moment du chargement des instructions, leurs adresses sont testées dans la BHT. Si un branchement est prédis pris, l'instruction contient suffisamment d'informations sur l'adresse cible (grâce à l'étape de prédécodage) pour initialiser un chargement à partir du cache d'instructions. Si l'adresse cible est dans le cache primaire d'instructions, aucun cycle n'est perdu si la prédiction est juste. La présence de delay slot contribue à augmenter la complexité de gestion des branchements.
Pour prédire les adresses de retour de procédures, le Sparc64 implémente une table d'adresses de retour de quatre entrées indexée par le pointeur de la fenêtre courante.
Par ailleurs, des points de reprises (ou checkpoint selon la terminologie employée) sont effectués avant l'émission d'instructions qui peuvent altérer l'état visible de la machine. Il n'est pas nécessaire de sauvegarder directement le contenu des registres, seule la table de correspondance utilisée par le renommage est conservée. Le Sparc64 supporte 16 niveaux de points de reprises. La mise en oeuvre d'un tel mécanisme permet la restitution de l'état de la machine en un cycle. La table de mise en correspondance des registres est restitué à sa valeur précédente provoquant ainsi l'abandon des valeurs calculées de manière spéculative. L'unité de gestion des branchements maintient actives toutes les branches et s'assure que le résultat de l'unité fonctionnelle chargée d'évaluer la condition du branchement correspond bien à la valeur prédite. Si une mauvaise prédiction est détectée, l'unité de branchement la signale à l'unité responsable des points de reprises qui génère alors le procédé de restauration du système à un état correct.
Ce même mécanisme est utilisé pour la mise en oeuvre d'une gestion précise des exceptions. Dans ce dernier cas, la restauration de l'état de la machine peut prendre plusieurs cycles. Le processeur commence par restaurer l'état fourni par le premier point de reprise situé après l'instruction fautive (ceci prend un cycle comme dans le cas des branchements). Puis, le CPU peut << défaire >> quatre instructions tous les deux cycles jusqu'à atteindre l'instruction génératrice de l'exception (schéma similaire à celui du MIPS R10000 si ce n'est qu'il traite quatre instructions à chaque cycle).
La figure ![]() présente le pipeline du Sparc64. Les quatre
étages de base sont représentés en grisés. Les trois étages à la fin du
pipeline schématisent la gestion du retrait des instructions (mais n'altèrent
pas les performances) alors que les trois premiers représentent le
préchargement des instructions à partir du cache secondaire. Ces trois
étages sont transparents pour le CPU tant que le préchargement est bon,
sinon ils introduisent une pénalité dans le cas d'un branchement absent du
cache primaire.
présente le pipeline du Sparc64. Les quatre
étages de base sont représentés en grisés. Les trois étages à la fin du
pipeline schématisent la gestion du retrait des instructions (mais n'altèrent
pas les performances) alors que les trois premiers représentent le
préchargement des instructions à partir du cache secondaire. Ces trois
étages sont transparents pour le CPU tant que le préchargement est bon,
sinon ils introduisent une pénalité dans le cas d'un branchement absent du
cache primaire.
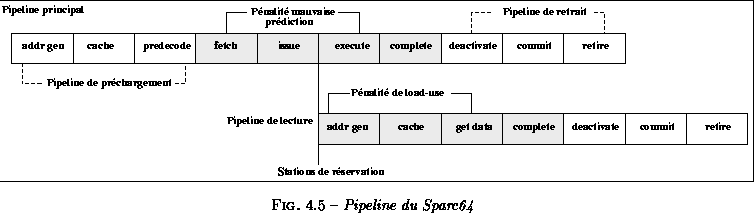
Le pipeline des instructions de lecture de la mémoire ajoute également trois cycles de pénalité si elles ne peuvent pas être anticipées.
Il est à noter que le Sparc64 supporte deux des modes mémoire de la norme
SPARC-V9 (voir chapitre ![]() ). Le mode
Total Store Ordering et le mode Relaxed Memory
ordering. Les opérations de lecture/écriture attendent dans un
premier temps le calcul des adresses avant d'être émises au rythme de
deux instructions à chaque cycle. Du fait de la division du cache de
données en deux bancs, une unité est implémentée pour chacun des bancs
pair et impair.
). Le mode
Total Store Ordering et le mode Relaxed Memory
ordering. Les opérations de lecture/écriture attendent dans un
premier temps le calcul des adresses avant d'être émises au rythme de
deux instructions à chaque cycle. Du fait de la division du cache de
données en deux bancs, une unité est implémentée pour chacun des bancs
pair et impair.
L'unité de gestion de la mémoire gère les communications entre le CPU, les caches et le reste du système. De plus, elle contrôle le bus d'interface avec la mémoire, de 128 bits, et le bus d'entrées/sorties, de 64 bits. Ce partitionnement permet au CPU et aux caches de ne fonctionner qu'avec un espace d'adressage virtuel, alors que la MMU maintient la cohérence de ces adresses avec le reste du système.
À la différence des autres processeurs, le Sparc64 utilise la totalité de l'adressage 64 bits et supporte trois niveaux d'adressage. Les adresses virtuelles sont dans un premier temps mappées vers des adresses logiques qui sont utilisées par le sous-système d'entrées/sorties ainsi que par la mémoire distribuée dans un environnement multiprocesseur. Ces adresses logiques sont alors converties en adresses physiques pour le système de mémoire local. Les adresses logiques fournissent une méthode pratique pour mettre en correspondance et partager les composants d'entrées/sorties et la mémoire (cette technique traduit une approche différente de celle d'IBM qui utilise une mémoire segmentée).
Pour assurer rapidement ces traductions d'adresses, le Sparc64 implémente deux types de tables de traduction communes pour les instructions et les données :
Le fait d'avoir séparé le CPU de l'unité de gestion de la mémoire permet d'augmenter la capacité de ces tables et améliore les performances sur les applications nécessitant de larges espaces de travail.
Par ailleurs, dans la mesure où le CPU peut générer trois adresses à chaque cycle (une pour le cache d'instructions et une pour chacun des bancs du cache de données), l'unité de gestion de la mémoire inclut un micro-TLB de huit entrées à trois ports. Ce micro-TLB effectue directement la traduction de l'adresse virtuelle en adresse physique en même temps que l'accès au cache. Si la traduction recherchée n'est pas présente elle est alors fournie par la combinaison VLB/TLB. Les défauts de TLB/VLB sont gérés par matériel à travers le mécanisme de traduction défini par l'architecture SPARC.
Un contrôleur de mémoire externe est nécessaire pour générer les signaux de contrôle pour la DRAM. Lors d'un défaut de cache primaire, la pénalité est de l'ordre de 21 cycles selon l'implémentation.
Un bus de 64 bits (le Hal I/O) est utilisé pour relier le processeur aux composants d'entrées/sorties. Ce bus multiplexé fonctionne à la fréquence de 50 MHz. Hal développe actuellement des passerelles vers les bus SBus et SCSI.
Le Sparc64 intégre de nombreuses caractéristiques permettant la détection et la correction d'erreur. Le cache primaire est protégé par parité, les données erronées étant relues à partir du cache secondaire. Le cache de données (ainsi que la mémoire principale) est protégé par ECC à raison de huit bits par mot de 64 bits. Ces huit bits permettent la correction d'erreur simple et la détection d'erreur double.
Le VLB et le TLB, ainsi que tous les signaux qui traversent les circuits sont également protégés par parité. Les erreurs pouvant être corrigées sont enregistrées et signalées selon un faible niveau de priorité. Les erreurs non recouvrables par matériel provoquent une interruption à haute priorité et font passer le CPU en mode RED_state selon la norme SPARC-V9. À partir de cet état, le Sparc64 peut charger des instructions de diagnostic à travers un bus série géré par la MMU. Ces instructions sont exécutées séquentiellement. Cette procédure, bien que lente, permet le diagnostic d'erreur dans le cache, dans la mémoire principale ou dans le CPU. Dans la plupart des cas, ce diagnostic peut invalider l'unité défectueuse, abandonner les processus affectés et redémarrer le système.
Hal espère que ces caractéristiques de fiabilité offriront au Sparc64 un avantage sur les autres processeurs dans le domaine des applications nécessitant une haute intégrité des données. Seuls les systèmes à base de processeur IBM RS/6000 atteignent un niveau équivalent de fiabilité. Ceci n'est pas sans rappeler que le fondateur de Hal a participé au développement de ces systèmes
Nous passerons rapidement sur les détails d'implémentation physique de ce
processeur. Il est implémenté sous la forme d'un conditionnement MCM
céramique basé sur la technologie des mainframe de Fujitsu. Il est
conçu selon une technologie CMOS à 0.4 m avec quatre couches de métal
et contient au total 21.9 millions de transistors, l'essentiel étant
constitué par la mémoire (2.7 millions pour le CPU). Séquencé à la fréquence
de 154 MHz, il dissipe environ 60 Watt.