



Next: Prédiction de branchement
Up: Séquencement et exécution
Previous: Unités entières et
Les mécanismes de chargement et de séquencement des instructions sont particulièrement importants et complexes sur les architectures superscalaires. Les microprocesseurs présentés sont capables d'exécuter 4, 5 ou 6 instructions par cycle. Aussi, le flot d'instructions lues en mémoire doit être élevé et soutenu. Par ailleurs, ce flot d'instructions peut être ralenti par des branchements, des dépendances de données, des défauts des caches d'instructions ou de données... Aussi des solutions pour limiter les pertes de performance ont été mises en oeuvre à tous les niveaux : prédiction dynamique de branchements, exécution dans le désordre, préchargement des instructions, renommage de registres, caches non bloquants, etc.
Nous détaillons ici les divers mécanismes de chargement et de séquencement des instructions pour les trois microprocesseurs étudiés. Les mécanismes de résolution des dépendances de données et de prédiction de branchement seront étudiés dans les paragraphes  et .
et .
Les mécanismes de chargement (figure ) et de séquencement des instructions sont responsables du maintien d'un flot d'instructions continu aux unités fonctionnelles, malgré les branchements et les défauts de cache d'instructions.
Le MIPS R10000 intègre un cache d'instructions de 32 Koctets associatif par ensemble à deux voies. Le MIPS R10000 prédécode les instructions quand elles sont chargées dans le cache. Quatre bits de prédécodage sont associés à chaque instruction. Ces bits permettent de déterminer rapidement, pour chaque instruction, la file d'attente vers laquelle elle doit être dirigée. Le microprocesseur charge jusqu'à quatre instructions par cycle à partir du cache d'instructions, et les décode au cycle suivant. Si le groupe chargé contient une instruction de branchement, la direction et la cible du branchement sont prédites. Si le branchement est prédit <<pris>>, l'adresse cible est immédiatement calculée et envoyée au cache d'instructions de manière à rediriger le flot des instructions. Étant donné qu'il faut un cycle pour décoder un branchement, une <<bulle>> est créée dans le flot des instructions : c'est-à-dire qu'aucune instruction n'entre dans les files d'attente au cycle suivant. Les instructions chargées durant ce cycle, désormais inutiles, sont sauvées dans le Resume Cache. Ce tampon est composé de quatre entrées de quatre instructions. S'il s'avère que la prédiction est fausse, les instructions sont directement chargées à partir du Resume Cache, réduisant ainsi la pénalité de branchement d'un cycle.

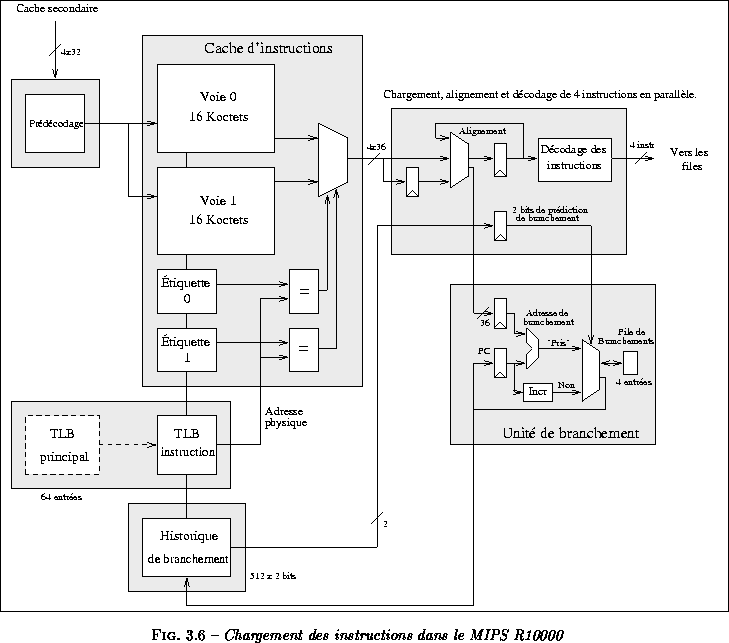
Après le décodage (y compris le renommage des registres logiques), les instructions sont émises vers les trois files d'attente de 16 entrées chacune :
- une file d'attente pour les instructions entières ;
- une file d'attente pour les instructions flottantes ;
- une file d'attente pour les instructions mémoires. Cette file lance les instructions vers l'unité load/store. Elle est organisée comme une FIFO (First-In First-Out) circulaire. Cette FIFO maintient l'ordre du programme original. La génération des adresses se fait dans l'ordre, et ne nécessite pas la présence de la donnée à écrire lors des écritures. Les lectures en mémoire peuvent être effectuées avant les écritures, mais il y a une détection des dépendances de type Read After Write sur les accès afin de respecter la sémantique de l'ordre séquentiel des instructions.
Si cela est nécessaire, les quatre instructions peuvent être écrites dans la même file d'attente. Seule une file d'attente pleine peut empêcher l'émission de quatre instructions. Mais cette situation devrait arriver rarement, car les trois files d'attente possèdent chacune 16 entrées.
Seules les instructions de multiplication et de division entières peuvent bloquer l'unité de chargement. En effet, ces instructions écrivent dans deux registres destinations, ce qui cause un conflit pour la logique de renommage.
Les instructions présentes dans les files d'attente peuvent être séquencées quelque soit leur position dans la file. Elles sont dites exécutables dès que tous leurs opérandes sont valides. Les autres instructions attendent un ou plusieurs opérandes. À chaque cycle, toutes les files d'attente sont mises à jour. De nouvelles instructions deviennent prêtes à être exécutées en fonction des registres calculés au cycle précédent.
À chaque cycle, une seule instruction peut être séquencée dans une unité fonctionnelle. Ses opérandes sont lus sur les fichiers de registres centralisés (flottants et entiers). Si plusieurs instructions sont prêtes à être exécutées pour une unité fonctionnelle donnée, l'une d'elles est choisie suivant des ordres de priorité. En général, la priorité est donnée aux plus anciennes instructions. Mais par exemple, sur l'ALU1, les branchements conditionnels sont prioritaires ; ceci afin de minimiser la pénalité d'une mauvaise prédiction de branchement. Pour les instructions de la file d'attente des instructions mémoire, la priorité est toujours donnée à l'instruction la plus ancienne dans la file d'attente.
Les instructions envoyées dans les files d'attentes sont aussi placées dans l'Active List. Cette liste permet de maintenir en apparence un ordre sur l'exécution des instructions, même si les instructions sont exécutées de manière spéculative ou dans le désordre. Cette liste peut gérer jusqu'à 32 instructions consécutives. Une instruction ne peut être retirée de la liste que si son exécution est terminée ainsi que l'exécution de toutes les instructions antérieures : retirer une instruction de l'Active List, c'est valider son exécution. Jusqu'à quatre instructions peuvent être retirées de la file d'attente par cycle, avec au maximum un seul store (le store effectif en mémoire est fait à ce moment).
Si une instruction provoque une exception, l'Active List est utilisée pour défaire successivement les actions de toutes les instructions postérieures exécutées spéculativement. Ceci est effectué à travers la table de renommage de registres.
L'UltraSPARC met en oeuvre des mécanismes de lancement plus simples que ceux du MIPS R10000, car il lance les instructions dans l'ordre. Cependant grâce à l'utilisation d'une file d'instructions, les instructions venant de groupes chargés à des cycles différents peuvent être lancées au même cycle.
L'unité de préchargement et de lancement (PDU) de l'UltraSPARC (voir la figure ) est chargée de précharger et d'émettre les instructions vers les unités d'exécution.
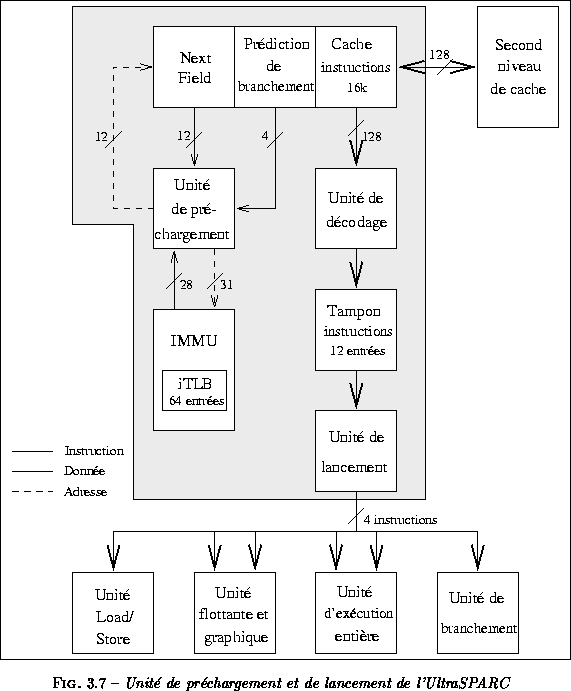
L'UltraSPARC intègre un cache d'instructions de 16 Koctets associatif par ensemble à 2 voies. Comme sur le MIPS R10000, les instructions chargées dans le cache de l'UltraSPARC sont partiellement décodées. Le cache peut émettre quatre instructions alignées par cycle vers le tampon d'instructions. Le mécanisme de prédiction de branchement utilisé dans l'UltraSPARC est présenté au paragraphe . Dans le tampon d'instructions, les instructions sont étendues à 62 bits pour permettre une détection rapide des dépendances de données et de ressources. Ce tampon, de 12 entrées, est géré de façon FIFO et peut émettre jusqu'à quatre instructions dans l'ordre à chaque cycle.
Les instructions sont classées par catégories : instructions de contrôle, load/store, instructions entières, instructions flottantes et graphiques... Au cours de l'étage de groupement du pipeline, un groupe d'au plus quatre instructions consécutives exécutables en parallèle est formé. En plus du respect des dépendances de données, il existe de nombreuses règles de groupement [11] :
- deux instructions au plus pour l'unité entière et deux instructions au plus pour l'unité flottante ;
- une seule instruction load/store par groupe ;
- les instructions qui ont le même registre de destination ne peuvent pas être groupées ;
- l'instruction load ou store doit être placée parmi les trois premières instructions du groupe ;
- les instructions entières doivent être placées parmi les trois premières instructions du groupe ;
- à chaque cycle, au maximum deux instructions flottantes ou graphiques peuvent être émises.
Une comparaison peut être faite avec le DEC 21164 [4] : ce microprocesseur utilise la même approche que l'UltraSPARC. L'émission des instructions dans les diverses unités fonctionnelles est synchrone et se fait toujours dans l'ordre. L'Ibox émet les instructions en fonction de diverses règles d'ordonnancement. La grande différence de philosophie entre le DEC 21164 et l'UltraSPARC concerne le groupement des instructions. Il est dynamique sur l'UltraSPARC, mais confiné à un bloc de quatre instructions alignées sur le DEC 21164.
Le PentiumPro intègre un cache d'instructions de 8 Koctets associatif par ensemble à quatre voies. Ce petit cache est soutenu par un deuxième niveau de cache très rapide de 256 Koctets à l'intérieur du même boîtier. La figure montre le détail de l'unité de chargement et de décodage du PentiumPro.
À chaque cycle d'horloge, le PentiumPro peut charger 16 octets alignés en mémoire, à partir du cache dans un tampon d'instructions. Ce flot d'instructions est envoyé vers trois décodeurs d'instructions qui vont traduire les instructions en micro-opérations. Le premier décodeur peut traduire n'importe quelle instruction et produire jusqu'à quatre micro-opérations. Les deux autres décodeurs se restreignent aux instructions simples se traduisant en une seule micro-opération . À noter que les instructions sont toujours décodées dans l'ordre. Les instructions les plus complexes, décodées par le décodeur général, utilisent un support matériel appelé Microcode Instruction Sequencer pour générer le flot de micro-opérations approprié. Ces instructions complexes peuvent occuper le décodeur pendant plusieurs cycles.
. À noter que les instructions sont toujours décodées dans l'ordre. Les instructions les plus complexes, décodées par le décodeur général, utilisent un support matériel appelé Microcode Instruction Sequencer pour générer le flot de micro-opérations approprié. Ces instructions complexes peuvent occuper le décodeur pendant plusieurs cycles.
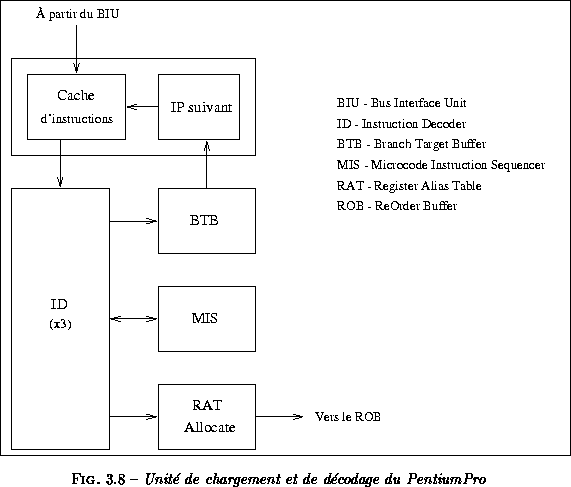
Après le décodage, les micro-opérations sont envoyées dans le ReOrder Buffer (ROB) ; ce tampon permet de maintenir l'ordre sémantique de l'exécution du programme : les micro-opérations sont exécutées dans le désordre mais validées dans l'ordre dans ce tampon. Chacune des 40 entrées du ROB possède un champ servant à mémoriser un résultat ou des codes conditions modifiés par la micro-opération. Nous détaillerons le ROB et le mécanisme de renommage de registres au paragraphe .
Ces micro-opérations sont ensuite placées dans une station de réservation de 20 entrées. Elles vont y rester jusqu'à ce que leurs opérandes sources soient valides. À chaque cycle, jusqu'à cinq micro-opérations peuvent être lancées : deux opérations de calcul, un load, un store, un calcul d'adresse pour un store (il faut deux micro-opérations pour réaliser une écriture mémoire : le calcul de l'adresse et le rangement lui même).
Dans de nombreuses situations, il y a beaucoup plus de micro-opérations prêtes à être exécutées que d'unités fonctionnelles. Dans ce cas, la logique de lancement utilise des règles de priorité.
Next: Prédiction de branchement
Up: Séquencement et exécution
Previous: Unités entières et