



Next: Mécanismes de chargement
Up: Séquencement et exécution
Previous: Partitionnement du pipeline
Cette section décrit les unités entières et l'unité de calcul d'adresses. Pour chaque microprocesseur, ces unités regroupent les unités arithmétiques et logiques, l'unité de multiplication et de division, l'unité de calcul d'adresses, le fichier de registres entiers...
Le MIPS R10000 intègre deux unités arithmétiques et logiques entières (ALU1 et ALU2), et une unité de calcul d'adresses.
Les deux unités arithmétiques et logiques traitent les opérations d'addition, les opérations de soustraction et les opérations arithmétiques et logiques. Leurs instructions sont fournies par la même file d'attente (file des opérations entières). Les unités ALU1 et ALU2 ne sont pas symétriques. Ainsi, l'ALU1 traite les instructions de branchement et de décalage, tandis que l'ALU2 traite toutes les opérations de multiplication et de division utilisant des algorithmes itératifs.
Au cours d'une multiplication, les opérations exécutées en un seul cycle peuvent être traitées par l'ALU2 pendant que le multiplieur est occupé. Par contre, dès que la multiplication est finie, l'ALU2 est occupée pendant 2 cycles durant lesquels le résultat est chargé dans les deux registres : EntryHi et EntryLo. L'ALU2 est occupée pendant toute la durée d'une division.
L'unité Load/Store lit les instructions depuis la file d'attente des opérations d'accès à la mémoire. Les adresses sont calculées dans l'ordre du programme mais les lectures peuvent dépasser les écritures avec détection des aléas Read After Write.
L'unité d'exécution entière de l'UltraSPARC est responsable des calculs entiers et du séquencement des pipelines. Cette unité est composée (figure  ) :
) :
- d'un fichier de registres entiers avec un système de fenêtrage. Sept ports en lecture (six ports pour les trois premières instructions et un port pour la donnée à écrire en mémoire pour un store) et trois ports en écriture (deux ports pour les pipelines entiers et un port pour l'écriture des données lues par les loads) sont implémentés ;
- de deux unités arithmétiques et logiques 64 bits traitant les opérations arithmétiques et logiques ainsi que les opérations de décalage ;
- d'une unité de calcul d'adresses pour les instructions load et store ;
- d'un multiplieur et diviseur entier, contenus dans l'une des unités arithmétiques et logiques, capables de calculer deux bits par cycle pour une multiplication et un bit par cycle pour une division. On remarque la latence particulièrement longue du multiplieur : l'UltraSPARC est l'héritier du SPARC V7 qui n'avait pas de multiplieur entier ;
- de l'unité de complétion et d'un mécanisme de chaînage pour les opérandes sources.

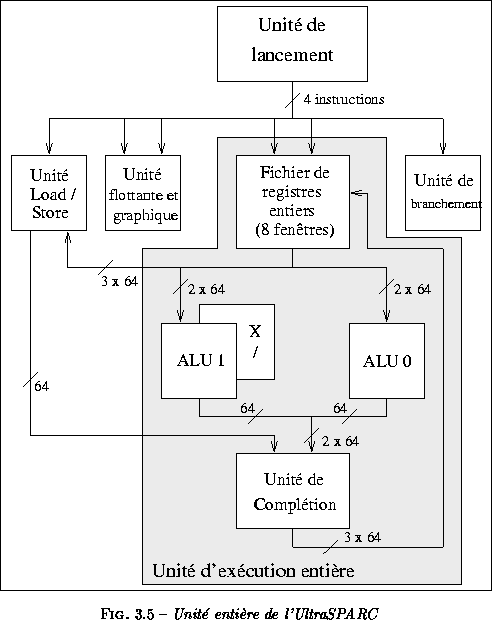
Les opérandes source des trois premières instructions sont chargées au cours de l'étage de groupement. Le mécanisme de chaînage charge les opérandes à partir des résultats des opérations précédentes (directement à la sortie des unités d'exécution), à partir du fichier de registres ou à partir de l'unité de complétion. Les opérations entières sont effectuées généralement en un seul cycle. Si l'instruction n'est pas interrompue par une exception ou une interruption, son résultat peut être écrit dans le fichier de registres. Cependant, les résultats d'un load ou d'une opération arithmétique et logique sont conservés respectivement quatre ou cinq cycles dans l'unité de complétion pour permettre une gestion précise des exceptions. Ce mécanisme simplifie la logique de contrôle mais complique le mécanisme de chaînage (voir ).
L'unité load/store calcule les adresses virtuelles. L'accès au cache à lieu au cycle suivant pour les loads, mais est différé jusqu'au cycle Write Back (au plus tôt !) pour les stores. Un load ou un store d'un double-mot s'effectue en deux cycles . Tous les stores flottants en simple ou double précision se font en un cycle.
. Tous les stores flottants en simple ou double précision se font en un cycle.
Le PentiumPro possède deux unités entières différentes et deux unités de calcul d'adresses. Ces unités sont connectées au bus de chaînage pour transférer plus rapidement leur résultat aux autres unités fonctionnelles.
- Unité entière N1 :
- L'unité entière N1 intègre de plus l'unité flottante. De ce fait, le bus de données de l'unité N1 est de 80 bits (les autres unités d'exécutions n'utilisent que des bus de 32 bits). Outre l'unité flottante, l'unité N1 comprend un multiplieur entier, un diviseur entier, une unité de décalage entière et une unité arithmétique et logique entière. Les multiplieurs et diviseurs entiers du PentiumPro sont particulièrement rapides (4 cycles de latence pour le multiplieur !).
- Unité entière N2 :
- Cette seconde unité inclut uniquement une unité arithmétique et logique entière simple (pas de multiplieur, de diviseur, ni d'unité de décalage). Cette unité effectue de plus tous les calculs d'adresse de branchement.
- Unités de calcul d'adresses :
- Le PentiumPro implémente deux unités de calcul d'adresses. Une pour les loads et une pour les stores. Ces unités sont composées chacune d'un additionneur complexe à quatre entrées qui combine l'adresse de base, l'adresse du segment, la valeur du déplacement et la valeur du registre de décalage. Chaque unité possède son propre port sur la station de réservation, ce qui permet au PentiumPro d'effectuer une lecture et une écriture sur le cache de données, à chaque cycle d'horloge.
Next: Mécanismes de chargement
Up: Séquencement et exécution
Previous: Partitionnement du pipeline