La norme SPARC-V9, comme sa prédécesseur la version 8, a été définie par SPARC International. SPARC-V8 définit une architecture de type 32 bits. Cette nouvelle architecture, tout en maintenant une compatibilité binaire introduit les caractéristiques suivantes :
Cette norme offre aux utilisateurs un espace d'adressage et de calcul de
type 64 bits et des instructions spécifiques ŕ un environnement
multiprocesseur.
Nous présentons dans ce chapitre cette nouvelle norme ŕ travers l'étude
du jeu d'instructions et quelques caractéristiques de son implémentation.
L'architecture SPARC-V9 reconnaît les types fondamentaux suivants
(tableau ![]() ) :
) :

L'architecture SPARC-V9 met en oeuvre les quatre modes d'adressage classiques déjŕ mis en oeuvre dans la norme SPARC-V8, ŕ savoir les modes d'adressage absolu, indirect, basé et indexé. La valeur des immédiats est signée et codée sur 13 bits.
Les instructions définies par cette architecture se répartissent dans les types de base suivant :
L'architecture SPARC étant une architecture load/store, les seules instructions d'accčs ŕ la mémoire sont des instructions de lecture ou d'écriture.
Le jeu d'instructions SPARC inclut des instructions atomiques d'accčs ŕ la mémoire. Il est ŕ noter que les données en mémoire doivent ętre alignées sur des frontičres respectant le format de la donnée accédée. Par défaut, l'ordre des données en mémoire est big-endian. Cependant, la norme SPARC-V9 introduit la possibilité de passer ŕ un format little-endian grâce ŕ un bit de configuration.
Le jeu d'instructions défini par l'architecture SPARC-V9 introduit un
nouveau type d'instructions de lecture qui permet au compilateur de
déplacer une instruction de lecture classique en amont de la structure
de contrôle qui garantit son usage. La sémantique de cette instruction
est la męme que les autres si ce n'est qu'elle ne provoque par
d'exception lorsqu'une erreur est détectée. Une valeur nulle est alors
renvoyée (d'oů le nom de cette instruction appelée non-faulting
load). L'exemple ![]() illustre son
usage. Cette optimisation est particuličrement utile dans un
contexte superscalaire.
illustre son
usage. Cette optimisation est particuličrement utile dans un
contexte superscalaire.
Une autre particularité du jeu d'instructions définie par la norme SPARC-V9 concerne l'introduction d'instructions de préchargement qui se déclinent selon plusieurs versions :
Ces instructions permettent d'anticiper le chargement des données et
de procéder ŕ la résolution des défauts de cache ou de TLB si il y a
lieu. Le fait de disposer de plusieurs variantes permet de męler
logiciel et matériel afin d'améliorer les performances. Effectivement,
ces instructions fournissent au matériel une indication sur le mode
d'utilisation de la donnée préchargée. Ainsi, un préchargement pour
plusieurs lectures (cas le plus important) sera initié de maničre ŕ ce
que la donnée soit fournie avec des efforts
<< raisonnables >>![]() . Un
préchargement pour une lecture (la donnée ne sera lue qu'une
fois puis non réutilisée en lecture ou écriture), ne sera exécuté que
si il perturbe le moins possible le cache (pas de réécriture
de données dans le cache).
. Un
préchargement pour une lecture (la donnée ne sera lue qu'une
fois puis non réutilisée en lecture ou écriture), ne sera exécuté que
si il perturbe le moins possible le cache (pas de réécriture
de données dans le cache).
Il est ŕ noter que ces diverses variantes ne sont pas utilisées pour le
préchargement des instructions. Ce cas est traité ŕ travers
l'instruction de branchement BPN (Branch Never with
Prediction) qui est interprété par le processeur comme le
préchargement de la cible jamais prise !
La norme SPARC-V9 reprend et améliore le modčle de mémoire précédemment
introduit dans la norme SPARC-V8. Ce modčle spécifie le comportement de la
mémoire dans des systčmes monoprocesseurs ou multiprocesseurs ŕ mémoire
partagée. La norme SPARC-V8 introduisait trois modes de fonctionnement :
La norme SPARC-V9 introduit un nouveau modčle de mémoire appelé Relaxed Memory Order (RMO). Ce modčle de mémoire impose peu de contraintes et permet de séquencer les accčs ŕ la mémoire (lecture ou écriture) dans n'importe quel ordre tant que le résultat reste juste. Il constitue donc le mode de fonctionnement le plus performant. Lorsqu'une nécessité d'ordonnancement est requise, elle doit ętre explicitement formulée dans le programme par l'instruction MEMBAR.
L'instruction MEMBAR pour memory Barrier sert deux fonctions distinctes :
Cette deuxičme fonctionnalité est nécessaire lorsque l'on souhaite que l'effet de cette instruction soit globalement visible au lieu de s'appliquer localement. Elle introduit alors un ordre dans le flot d'exécution des instructions en fonction de la commande passée en paramčtre. Ce paramčtre est codé dans le champ de l'instruction. Ainsi :
Un panachage des masques est également possible, un paramčtre par
exemple (#LoadLoad | #StoreStore) ordonne les lectures, les
écritures mais n'introduit aucune contrainte entre les lectures et les
écritures et vice-versa.
Le jeu d'instructions défini par la norme SPARC-V9 inclut également des instructions d'accčs ŕ la mémoire spécifiques ŕ un systčme multiprocesseur. Ces instructions permettent de mettre en oeuvre des primitives de synchronisation utilisées par les mécanismes d'exclusion mutuelle. On peut citer :
Ces instructions correspondent aux instructions classiques de calcul entier, ainsi qu'aux opérations de test et de décalage.
L'instruction de multiplication entičre prend deux opérandes 64 bits pour
fournir un résultat sur 64 bits, de męme que la division. Par ailleurs, pour
des raisons de compatibilité avec la norme SPARC-V8, des instructions de
type (32 x 32 ~ 64 bits) et (64
32 ~
32 bits) sont incluses.
La norme SPARC-V9 introduit en outre l'ensemble des instructions relatives au calcul sur 64 bits.
L'architecture SPARC fournit des instructions d'addition et de soustraction << étiquetées >>. Ces instructions sont utiles pour les langages Lisp et Smalltalk. L'étiquette concerne les deux bits de poids faible des opérandes. Si l'une ou l'autre de ces étiquettes est non nulle ou si un débordement de capacité survient alors un overflow est signalé.
Ces instructions effectuent l'ensemble des calculs arithmétiques flottants conformes ŕ la norme IEEE 754-1985 (en ce qui concerne les données 32 et 64 bits. Pour les données 128 bits la norme en vigueur est alors la IEEE Standard for Shared Data Formats 1596.5-1993).
La norme SPARC-V9 définit 32 registres flottants simple-précision (32 bits),
32 registres double-précision (64 bits) et 16 registres flottants de 128
bits. Nous reviendrons au chapitre ![]() sur le
détail de leur implémentation.
sur le
détail de leur implémentation.
De męme que MIPS, SPARC a fait le choix de mettre en oeuvre des branchements retardés. Un bit de l'instruction de transfert permet d'annuler cette instruction. Il est ŕ noter que dans le cas de la norme SPARC-V8, cette instruction était chargée ŕ partir du cache męme en cas d'annulation. La norme SPARC-V9 améliore cet aspect en ne chargeant l'instruction que si elle est exécutée. Ceci, permet d'éviter le traitement des défauts de caches sur instruction annulée.
Les instructions de transfert de contrôle sont relatives au PC. Ces
déplacements sont variables et sont explicités au tableau ![]() . Il est ŕ noter que dans le cas des instructions de jump and
link, l'adresse de retour est conservée dans un registre spécifié par
l'instruction.
. Il est ŕ noter que dans le cas des instructions de jump and
link, l'adresse de retour est conservée dans un registre spécifié par
l'instruction.

Ces instructions sont similaires aux instructions mises en oeuvre sur
l'architecture DEC. Elles effectuent la copie d'une registre source vers un
registre destination selon la valeur d'un code condition entier ou flottant
ou selon le contenu d'un registre entier. Ces instructions augmentent les
performances en réduisant le nombre de branchement.
Pour plus de détails sur l'évolution de l'architecture SPARC, nous renvoyons
le lecteur ŕ [10].
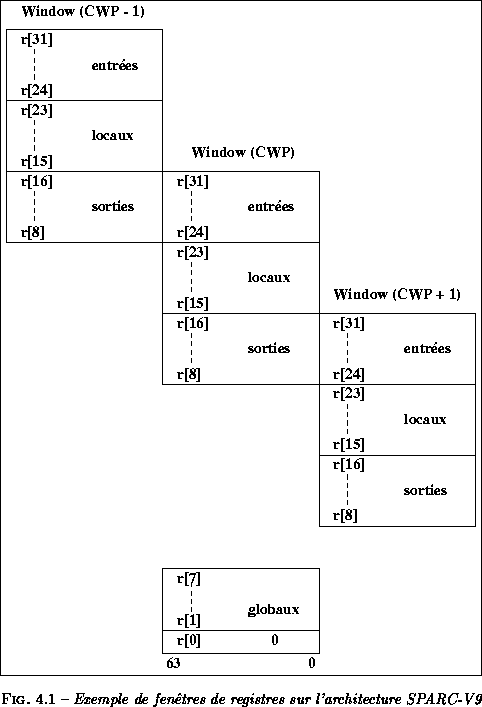
L'architecture SPARC met en oeuvre des fenętres de registres. Ce choix a été motivé par des études qui ont montré (selon [11]) que la sauvegarde des registres lors des appels de procédures et leur restitutions ŕ leur retour peut coűter entre 5%ŕ 40%des références mémoires. Une alternative est d'utiliser plusieurs bancs de registres et d'en allouer un nouveau ŕ chaque nouvel appel de procédure. Pour éviter d'ętre limité dans ces appels, les bancs de registres sont organisés sous la forme d'une file circulaire. Cette technique est appelée fenętre de registres.
L'une des difficultés est de passer les paramčtres. Si chaque procédure ŕ son propre ensemble de registres, aucune donnée ne peut ętre partagée. L'un des moyens de résoudre cet inconvénient est de permettre un recouvrement des fenętres de registres de maničre ŕ disposer d'une zone commune pour passer les paramčtres. C'est cette technique qui a été mise en oeuvre sur l'architecture SPARC.
L'unité entičre peut contenir, selon la norme SPARC-V9, de 64 ŕ 528
registres généraux de 64 bits. Ils sont partitionnés en huit registres
globaux, huit registres << d'alternance >> globaux destinés au mode privilégié ![]() , plus un nombre d'ensemble de
16 registres dépendant de l'implémentation matérielle (ce nombre étant
compris entre 3 et 32).
, plus un nombre d'ensemble de
16 registres dépendant de l'implémentation matérielle (ce nombre étant
compris entre 3 et 32).
Une fenętre de registres consiste en huit registres d'entrée, huit registres locaux et huit registres de sortie.
Ŕ n'importe quel moment, une instruction peut accéder aux huit
registres globaux et aux 24 registres de la fenętre courante. La
fenętre de registres comprend les huit registres d'entrées et locaux
d'un ensemble particulier, plus les huit registres d'entrées d'un
ensemble adjacent, adressés ŕ partir de la fenętre courante comme des
registres de sortie. La figure ![]() illustre cette mise en oeuvre. La fenętre courante est désignée par
un pointeur (nommé CWP sur la figure pour Current Window
Pointer).
illustre cette mise en oeuvre. La fenętre courante est désignée par
un pointeur (nommé CWP sur la figure pour Current Window
Pointer).
Comme on l'a dit précédemment, la norme SPARC-V9 impose :
Ŕ la différence des fenętres de registres entiers, l'ensemble des registres
flottants est accessible ŕ tout moment. Ces registres sont lus et écrits par
l'ensemble des instructions de calcul arithmétiques flottantes ainsi que par
les instructions de lecture/écriture. Il existe cependant une astuce au
niveau du numéro de codage de ces registres en fonction du type de données
accédées. Le tableau ![]() explicite
cette mise en correspondance.
explicite
cette mise en correspondance.
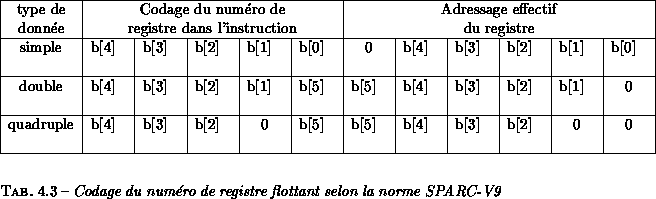
Former un mot quadruple par concaténation de registres simple précision n'est pas une manipulation qui est considérée comme importante.
Sur les processeurs d'architecture antérieure ŕ la norme SPARC-V9, les
exceptions sont gérées en allouant une nouvelle fenętre de registres et
en sauvant le PC ainsi que le futur PC dans deux registres de cette
fenętre, les bits d'états critiques étant sauvegardés dans le registre
PSR (Processor State Register).
Pour la gestion des exceptions, la norme SPARC-V9 implémente une pile
de registres pour sauvegarder l'état courant du processeur, rendant
inutile le changement de fenętres. Cette pile de registres
permet de sauvegarder les deux PC, le type de l'exception et
l'état courant du processeur (codes conditions, registre
d'identification de l'espace d'adressage, registre d'état du
processeur, pointeur sur la fenętre courante de registres). Quatre
niveaux de pile constituent le minimum spécifié par la norme SPARC-V9
qui peut aller jusqu'ŕ sept niveaux d'interruption.
On peut également remarquer que sur la norme SPARC-V8, les routines d'exceptions étaient quittées par l'instruction RETT exécutée dans le delay slot de l'instructions de branchement qui la précédait. Cette instruction est désormais remplacée par les instructions DONE et RETRY qui restitue l'état du processeur de façon atomique.
Dans la norme SPARC-V8, l'unité de gestion de la mémoire traduit les
32 bits d'adresses virtuelles et les 16 bits de numéro de contexte en
une adresse physique de 36 bits, en accédant ŕ quatre niveaux de
tables de page. De maničre générale, la traduction de ces adresses est
conservée dans la TLB, inhibant ainsi le besoin de passer par ces
tables. Mais quand un défaut de TLB est détecté, ces quatre niveaux
de tables permettent de retrouver l'adresse de la page physique. La
figure ![]() récapitule ce schéma de
traduction.
récapitule ce schéma de
traduction.
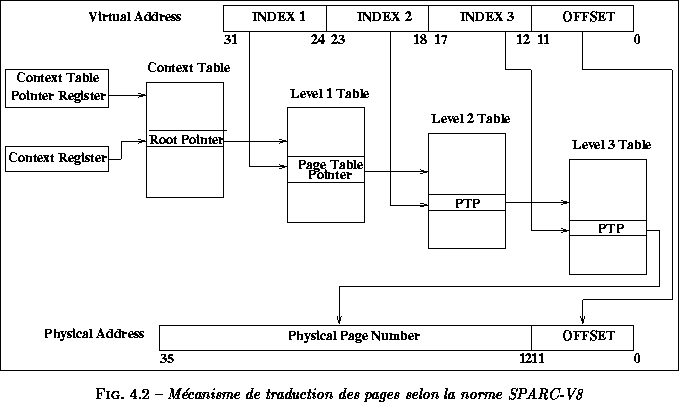
La taille des pages gérée par la MMU ŕ travers son mécanisme de
traduction d'adresse varie de 4 Ko ŕ un contexte de 4 Go, en passant
par les tailles intermédiaires de 256 Ko et 16 Mo. Dans ce cas, le
nombre de tables de pages adressées pour obtenir la traduction de
l'adresse diminue. Ainsi, dans le cas d'une page de 256 Ko, le champ
INDEX 3 de la figure ![]() est
joint au champ OFFSET et la table de niveau 3 n'est pas
adressée.
est
joint au champ OFFSET et la table de niveau 3 n'est pas
adressée.
La norme SPARC-V9 reprend le męme mécanisme de traduction
d'adresses. Elle définit des adresses virtuelles sur 44 bits et un
espace d'adressage physique sur 41 bits. Par ailleurs, quatre tailles
de pages sont supportées par l'unité de gestion de la mémoire : 8 Ko,
64 Ko, 512 Ko et 4 Mo.
Aprčs avoir expliqué quelques caractéristiques de cette architecture, nous
allons maintenant pouvoir aborder son implémentation ŕ travers l'étude des
microprocesseurs.