Les trois microprocesseurs étudiés utilisent des mécanismes de prédiction de branchement pour éviter de perdre tous ces cycles. La résolution du branchement n'est pas attendue pour charger les instructions suivantes, mais une prédiction est faite sur la direction du branchement et sa cible. Les instructions chargées après un branchement et avant sa résolution sont dites <<spéculatives>>, car elles sont simplement initialisées mais peuvent être avortées en cas de mauvaise prédiction de branchement.
Un bit de prédécodage est utilisé pour localiser immédiatement les instructions de branchement dans le pipeline de chargement. En cas de branchement conditionnel, la direction de branchement est prédite et la cible calculée. Un cycle est systématiquement perdu sur tout branchement prédit pris. Pour la prédiction de la direction de branchement le MIPS R10000 utilise une table de prédiction à deux bits, de 512 entrées gérée selon l'algorithme de Smith. La prédiction de la direction de branchement est prise en fonction de l'algorithme présenté à la figure ![]() .
.
Pour pouvoir rétablir l'état du microprocesseur en cas de mauvaise prédiction (le MIPS R10000 gère jusqu'à quatre branchements spéculatifs qui pourront être résolus dans n'importe quel ordre), le MIPS R10000 intègre une pile de branchements où sont rangées les informations nécessaires pour restaurer l'état du microprocesseur.
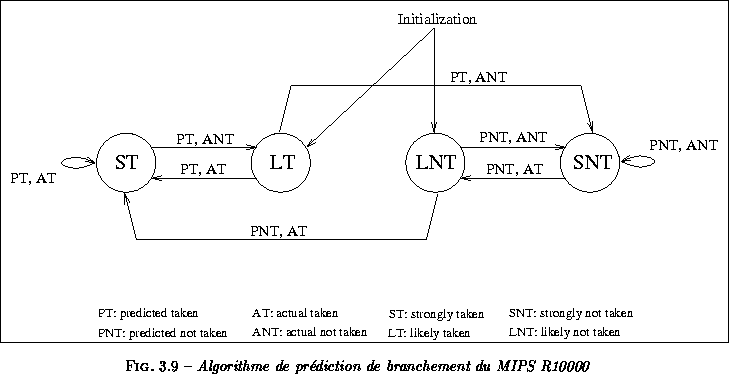
La résolution des branchements a lieu à l'étage 4 du pipeline. L'UltraSPARC utilise le même algorithme de prédiction de branchement à deux bits que le MIPS R10000 (voir figure ![]() ), mais la table de prédiction est intégrée dans le cache d'instructions de la manière suivante : un champ de deux bits est associé à chaque paire d'instructions. Cette structure assure que normalement une prédiction est associée pour chaque branchement présent dans le cache d'instructions, car le jeu d'instructions SPARC implémente les branchements retardés. L'UltraSPARC implémente ainsi une table de 2048 entrées. À noter qu'au chargement de l'instruction dans le cache, l'automate de prédiction est initialisé d'après le bit de prédiction statique (présent pour certains branchements).
), mais la table de prédiction est intégrée dans le cache d'instructions de la manière suivante : un champ de deux bits est associé à chaque paire d'instructions. Cette structure assure que normalement une prédiction est associée pour chaque branchement présent dans le cache d'instructions, car le jeu d'instructions SPARC implémente les branchements retardés. L'UltraSPARC implémente ainsi une table de 2048 entrées. À noter qu'au chargement de l'instruction dans le cache, l'automate de prédiction est initialisé d'après le bit de prédiction statique (présent pour certains branchements).
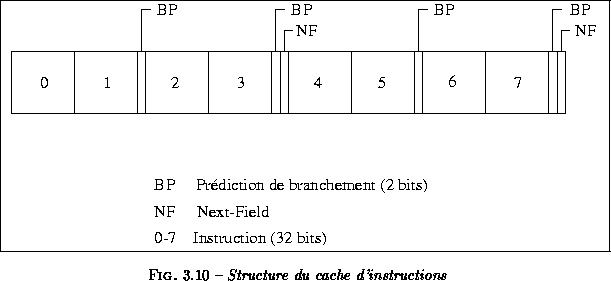
Pour prédire l'adresse de la cible, un mécanisme appelé Branch Following est implémenté. Un champ de 13 bits appelé Next-Field est inséré toutes les quatre instructions dans le cache d'instructions (figure ![]() ). Ce champ indique à quelle position dans le cache charger les instructions au prochain cycle. Les 12 premiers bits donnent la position dans le cache de la cible d'un branchement présent dans les 4 instructions, le dernier bit indique la place du groupe d'instructions en séquence (le cache d'instructions est <<pseudo-associatif>> par ensemble à deux voies, voir chapitre
). Ce champ indique à quelle position dans le cache charger les instructions au prochain cycle. Les 12 premiers bits donnent la position dans le cache de la cible d'un branchement présent dans les 4 instructions, le dernier bit indique la place du groupe d'instructions en séquence (le cache d'instructions est <<pseudo-associatif>> par ensemble à deux voies, voir chapitre ![]() ). On notera aussi que l'on ne prédit pas la cible, mais sa position dans le cache.
). On notera aussi que l'on ne prédit pas la cible, mais sa position dans le cache.
La pénalité d'une mauvaise prédiction de branchement est très importante (résolution du branchement à l'étage 10). Le PentiumPro utilise un Branch Target Buffer (BTB) de 512 entrées accédé en un cycle et prédisant à la fois la cible du branchement et la direction de branchement. Il n'y a donc pas de pénalité pour les branchements correctement prédits. Ce BTB est associatif par ensembles à quatre voies.
Contrairement au MIPS R10000 et à l'UltraSPARC, le PentiumPro n'utilise pas le traditionnel algorithme de Smith, mais une variante de la méthode de Yeh et Patt [15] utilisant la corrélation entre l'historique des derniers branchements et l'adresse. Ce schéma est plus efficace que le schéma classique à 2 entrées.
Dans le cas où un branchement est absent du BTB (cette situation est détectée au sixième étage du pipeline), le branchement est prédit pris si le déplacement est négatif et l'adresse cible est directement utilisée pour rediriger le flot d'instructions.
On notera l'effort d'intégration particulièrement important fait sur le BTB : 512 entrées, 4 voies associatifs, répondant en un cycle![]() alors que le cache d'instructions répond en 2 cycles et demi.
alors que le cache d'instructions répond en 2 cycles et demi.