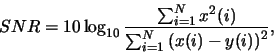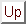



Next: Bark Spectral Distortion (BSD)
Up: State of the Art
Previous: State of the Art
Contents
Index
Objective Speech Quality Measures
There are several objective speech quality measures. The most simple one
is the Signal to Noise Ratio (SNR) that compares the original and
processed speech signals sample by sample. There are also more
complex ones that are built based on Human Auditory System model
involving complex mathematical calculations. We present the most famous
measures in this section. All of them with the exception of the ITU
E-model operates on both the original and the processed speech sample.
This limitation makes it impossible to work in real time and to include
these metrics in designing new mechanisms (rate control or speech codecs design
to take into account the user's perception and the network factors). A
second disadvantage is that the obtained results do not correlate always
with subjective data (thus they cannot measure correctly user's
perception). A third drawback is that some of them are computationally
extensive. This point limits their usage in lightweight applications
including mobile phones. Some of
these metrics are designed and optimized basically to consider encoding
impairments and restricted conditions, but they do not work efficiently
when they used in other conditions (ex. distortion due to the
transmission over the network). Some of these methods require a perfect
synchronization between the original and processed signals otherwise the
performce degrades considerably. In this case several factors including
the delay variation's effect cannot be taken into account by these methods.
There are three types of objective speech quality measures: time domain,
spectral domain, and perceptual domain measures [155]. The time
domain measures are usually applicable to analog or waveform coding
systems in which the goal is to reproduce the waveform itself. SNR and
segmental SNR (SNRseg) are the most known methods. Since the waveform
are directly compared in time domain, synchronization of the original
and distorted signals is a must. However, synchronization is difficult;
if not performed well, the performance is poor.
The most simple possible measure is the Signal-to-Noise (SNR) ratio. Its goal is to measure the distortion of the waveform coders that reproduce the input waveform. It is calculated as follows:
where 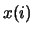 and
and 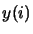 are the original and processed speech samples indexed by
are the original and processed speech samples indexed by 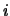 and N is the total number of samples.
Segmental Signal-to-Noise Ratio (SNRseg), instead of working on the whole signal, calculates the average of the SNR values of short segments (15 to 20 ms). It is given by:
and N is the total number of samples.
Segmental Signal-to-Noise Ratio (SNRseg), instead of working on the whole signal, calculates the average of the SNR values of short segments (15 to 20 ms). It is given by:
where 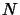 and
and 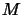 are the segment length and the number of
segments respectively. SNRseg gives better results than SNR for waveform
encoders, but it gives very bad results for vocoders (see Section 3.5).
The second type of measures are the spectral domain ones [155]. They are generally computed using speech segments typically between 15 and 30 ms long. They are much more reliable than time domain measures and less sensitive to the misalignments between the original and distorted signals. However, these measures are closely related to speech codec design and use the parameters of speech production modules. Hence their ability to adequately describe the listener's auditory response is limited by the constraints of the speech production modules. They include the log likelihood ratio, the Linear Predictive Coding (LPC) parameter distance measures, the cepstral distance, and the weighted slope spectral distance measures (for more details and descriptions see [155]). In general, all these methods gives good results for some encoding distortion, but they are not valid for the case when the original speech is passed through a communication system that significantly changes the statistics of the original speech.
The third type of objective measures is constituted by the perceptual
domain measures [155]. In contrast to the spectral domain
measures, perceptual domain measures are based on models of human
auditory perception. They transform speech signal into a perceptually
relevant domain such as bark spectrum or loudness domain, and
incorporate human auditory models. They give better prediction of the
quality under the condition that the used auditory model used truly describes the human auditorial system. It is clear that this task is very complex and it is not possible to implement exact model of such system. However, by using approximations of the human auditorial system, the obtained results correlate better than that of the other two types of speech measures. Another important point to underline is the fact that these models are optimized for a specific type of speech data; the performance is not good for different speech data. In addition, they have the risk of not describing perceptually important effects relevant to speech quality but simply a curve fitting by parameter optimization. These measures are the most known and used in the literature. We provide a brief description of these metrics as given in [155]. The evaluation of their performances is given in Section 5.5.
are the segment length and the number of
segments respectively. SNRseg gives better results than SNR for waveform
encoders, but it gives very bad results for vocoders (see Section 3.5).
The second type of measures are the spectral domain ones [155]. They are generally computed using speech segments typically between 15 and 30 ms long. They are much more reliable than time domain measures and less sensitive to the misalignments between the original and distorted signals. However, these measures are closely related to speech codec design and use the parameters of speech production modules. Hence their ability to adequately describe the listener's auditory response is limited by the constraints of the speech production modules. They include the log likelihood ratio, the Linear Predictive Coding (LPC) parameter distance measures, the cepstral distance, and the weighted slope spectral distance measures (for more details and descriptions see [155]). In general, all these methods gives good results for some encoding distortion, but they are not valid for the case when the original speech is passed through a communication system that significantly changes the statistics of the original speech.
The third type of objective measures is constituted by the perceptual
domain measures [155]. In contrast to the spectral domain
measures, perceptual domain measures are based on models of human
auditory perception. They transform speech signal into a perceptually
relevant domain such as bark spectrum or loudness domain, and
incorporate human auditory models. They give better prediction of the
quality under the condition that the used auditory model used truly describes the human auditorial system. It is clear that this task is very complex and it is not possible to implement exact model of such system. However, by using approximations of the human auditorial system, the obtained results correlate better than that of the other two types of speech measures. Another important point to underline is the fact that these models are optimized for a specific type of speech data; the performance is not good for different speech data. In addition, they have the risk of not describing perceptually important effects relevant to speech quality but simply a curve fitting by parameter optimization. These measures are the most known and used in the literature. We provide a brief description of these metrics as given in [155]. The evaluation of their performances is given in Section 5.5.
Subsections
Next: Bark Spectral Distortion (BSD)
Up: State of the Art
Previous: State of the Art
Contents
Index
Samir Mohamed
2003-01-08