



Next: New LM with Adaptive
Up: New Levenberg-Marquardt Training Algorithms
Previous: Analytical Formulation of the
Contents
Index
There are several methods to update the 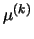 parameter at each step
parameter at each step 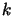 ; the main idea is to choose a value for which the error function is minimized. After initializing the weights randomly, the training algorithm using the LM method in general is as follows:
; the main idea is to choose a value for which the error function is minimized. After initializing the weights randomly, the training algorithm using the LM method in general is as follows:
- Present all inputs to the network and compute the corresponding
network outputs and errors from Eqns. 10.12 and 10.13, and
the sum of the squares of errors over all the inputs using Eqn. 10.14.
- Compute the Jacobian matrix based on Eqn. 10.18. The Hesssian matrix can be obtained from Eqn. 10.17; then the gradient vector is to be calculated from Eqn. 10.24.
- The weights adjustments
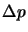 are obtained from Eqn. 10.21.
are obtained from Eqn. 10.21.
- Recompute the sum of squares using
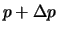 . If this new sum of squares is smaller than the one computed in step 1, then reduce
. If this new sum of squares is smaller than the one computed in step 1, then reduce 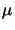 by
by 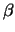 , let
, let 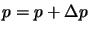 , and go back to step 1. If the sum of squares is not reduced, increase by and go back to step 3.
, and go back to step 1. If the sum of squares is not reduced, increase by and go back to step 3.
- The algorithm is assumed to converge when certain criteria are satisfied. The stop criteria may include: the value is greater or less than a predefined threshold, there is no adjustment on the weights, or the elements of the gradient vector
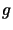 become zeros, a maximum number of iterations is reached, etc.
become zeros, a maximum number of iterations is reached, etc.
The parameter is initialized to a positive value (for example 0.01), is a constant and has a positive value (for example 10), 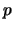 is the vector that contains the adjustable parameters, and is equivalent to the search direction
is the vector that contains the adjustable parameters, and is equivalent to the search direction 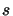 .
As described in [55], the Leveberg-Marquardt algorithm is a modification of the backpropagation algorithm to train ANN models. The only changes to this algorithm in order to apply it to RNN are the equations used to compute the outputs, errors, sum of squares of errors and the Jacobian matrix, given by equations 10.10 through 10.24.
There is another variant of the above algorithm, which differs only in the way the value of is updated. The idea is to keep it constant ``in the center'':
.
As described in [55], the Leveberg-Marquardt algorithm is a modification of the backpropagation algorithm to train ANN models. The only changes to this algorithm in order to apply it to RNN are the equations used to compute the outputs, errors, sum of squares of errors and the Jacobian matrix, given by equations 10.10 through 10.24.
There is another variant of the above algorithm, which differs only in the way the value of is updated. The idea is to keep it constant ``in the center'':
![\fbox{\parbox[c]{5in}{
\begin{tabbing}ifff \=yyyy \=xxxx \=zzzz \= uuuu \kill ...
... \> then $\mu=\mu * \beta$\\
\>\> else keep $\mu$\ as it is
\end{tabbing} }}](img492.gif)
where
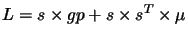 . The weights are updated only if
. The weights are updated only if 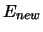 is less than the previous
is less than the previous 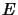 . We use this algorithm in all the results presented in the remaining of this Chapter.
One of the drawbacks of the LM method is that it requires a large amount of memory. In nowadays computers, this is not, in general a big issue. However, it must be observed that there is a slight modification to the above algorithm in order to use less memory space (referred as ``the reduced memory LM'') but it is slower. The difference is in the method used to compute the search direction. The Cholesky factorization is used to calculate it from the Hesssian matrix and the gradient vector.
. We use this algorithm in all the results presented in the remaining of this Chapter.
One of the drawbacks of the LM method is that it requires a large amount of memory. In nowadays computers, this is not, in general a big issue. However, it must be observed that there is a slight modification to the above algorithm in order to use less memory space (referred as ``the reduced memory LM'') but it is slower. The difference is in the method used to compute the search direction. The Cholesky factorization is used to calculate it from the Hesssian matrix and the gradient vector.
Next: New LM with Adaptive
Up: New Levenberg-Marquardt Training Algorithms
Previous: Analytical Formulation of the
Contents
Index
Samir Mohamed
2003-01-08