In this subsection, we compare the two considered types of neural networks: Artificial Neural Networks (ANN) and Random Neural Networks (RNN), in the context of our specific problem. This is based on our experience with both models.
We used the Neural Networks MATLAB Toolbox when working with ANN, and a MATLAB package [1] for RNN. We observed that ANN training process was relatively faster than that of RNN (to overcome this problem, we proposed several training algorithms for RNN with the aim of accelerating the training process, see Chapter 10). However, during run-time phase, RNN outperformed ANN in the total calculation time. This is because in the RNN's three-level architecture, the computation of the output for the unique output neuron is done extremely fast: the non-linear system of equations (3.2), (3.3) and (3.4) allows, in this topology, to compute the s of the input layer directly, and of hidden layer neurons from the values for input layer ones. To be more specific, for each input neuron we have
(where, actually, we choose to set
), and for each hidden layer neuron ,
The output of the black box is then , given by
(The cost of computing the output is exactly
products (or divisions) and the same number of sums, where is the number of input neurons and is the number of hidden ones.)
ANN's computations are slower because they involve nonlinear function calculations for each neuron in the architecture (sigmoid, tanh, etc.). This makes RNN particularly attractive for using them in contexts with real-time constraints, or for lightweight applications. This can be important in some kind of network applications, for example, in [83], an ANN packet-loss predictor is proposed for real-time multimedia streams. The prediction precision is good, but the calculation time is much more than the next packet arrival time which makes the system useless except for very powerful computers.
The most important feature of RNN we found for our problem is that they capture very well the mapping from parameters' values to the quality evaluation. This concerns also their ability to extrapolate in a coherent way for parameters' values out of the ranges used during the training phase. For instance, this led in [2] to build a zero-error channel decoder.
As previously mentioned, the most common problems of ANN's learning are the over-training and the sensitivity to the number of hidden neurons. The over-training problem makes the NN memorize the training patterns, but gives poor generalizations for new inputs. Moreover, if we cannot identify some near-optimal number of hidden neurons, the performance may be bad for both the training set and the new inputs. Figure 4.9(b) shows an example of an over-trained ANN network, where we can see irregularities, bad generalizations and bad capturing of the function mapping (see Subsection 7.4.3 for comparison with RNN).
We trained different architectures (varying the number of hidden neurons) for both ANN and RNN, with the same data (described in Section 6.3) and the same mean square error. Let us look, for instance, at the behavior of the quality as a function of the normalized bit rate BR (the 4 remaining variables were set to their most frequent observed values). In the database, BR varies between 0.15 and 0.7. In Figure 4.10(a) and Figure 4.10(b), we depict the ability of both networks to interpolate and extrapolate the results when BR varies from zero to its maximum value 1. These Figures show that RNN captures the mapping between the input and output variables, and that RNN is not very sensitive to the number of hidden neurons. While ANN gives quite different approximations for small changes in the size of the hidden layer.
Moreover, if the optimal ANN architecture could not be identified, its accuracy could be bad. Let us look now at the extreme values. If BR=0.0, the output should be around one, while for BR=1.0, the output should be between 8.5 and 9.0 on the y-axis. For the case of ANN, as shown in Figure 4.10(b), when the number of hidden neurons changes from four (optimal experimentally) to five, the generalization is bad, specially when BR goes to zero, where the output is 3.2 instead of 1. This gives RNN a better ability to generalize.
Figure 4.9:
The problem of overtraining using ANN
[Correctly trainined]
[Example of an over-trained ANN]
Figure 4.10:
Performance of ANN and RNN to interpolate and extrapolate for different number of hidden neurons
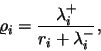


![\fbox{\includegraphics[width=0.45\textwidth]{IEEEFigsNew/ANN-simiGood.eps}}](img39.gif) [Example of an over-trained ANN]
[Example of an over-trained ANN]
![\fbox{\includegraphics[width=0.45\textwidth]{IEEEFigsNew/ANN-VeryBad.eps}}](img40.gif)
![\fbox{\includegraphics[width=0.45\textwidth]{IEEEFigsNew/Linear_Extrap_Rnn.eps}}](img310.gif) [Using ANN]
[Using ANN]
![\fbox{\includegraphics[width=0.45\textwidth]{IEEEFigsNew/Linear_Extrap_AnnBest.eps}}](img311.gif)