



Next: More than one Media
Up: Descriptions of Our New
Previous: Introduction
Contents
Index
Overview of the Method
In this Section, we describe the overall steps to be followed in order to build a tool to automatically assess in real time the quality of real-time media transmitted over packet networks. We henceforth mean by the term ``media'' any speech, audio, video, or multimedia streams. Here our goal is to describe our method regardless of the media type in hand. See Figure 4.1 and Figure 4.2.
First, we define a set of static information that will affect the general
quality perception. We must choose the most effective quality-affecting
parameters corresponding to the media-type applications and to the network that
will support the transmission. Then, for each parameter we must select several
values covering all the possible range for that parameter. More values should be
given in the range of the most frequent occurrences. For example, if the
percentage loss rate is expected to vary from 0 to 10 %, then we may use 0, 1,
2, 5, and 10 % as typical values for this parameter. This is provided that the
loss rate is generally between 0 and 5%, and the highest allowed value is 10%
in the range. (In this case, it is supposed that the quality is the worst for
10% loss and for normal values of the other parameters.) Note that, not all
media types tolerate the parameters' values in the same way. For example, speech
can tolerate up to 20% loss rate, while video may tolerate only up to 5 % of
loss rate without error resiliency in the encoder side. More values should be
used in the range where it is expected to be more frequent in reality. If we
call configuration of the set of quality-affecting parameters, a set of
values for each one, the total number of possible configurations is usually
large. We must then select a part of this large cardinality set, which will be
used as (part of) the input data of the NN in the learning phase.
To generate a media database composed of samples corresponding to different
configurations of the selected parameters (called ``Distorted Database''), a
simulation environment or a testbed must be implemented. This is used to send
media sequences from the source to the destination and to control the underlying
packet network. Every configuration in the defined input data must be mapped
into the system composed of the network, the source and the receiver. For
example, working with IP networks and video streams, the source controls the bit
rate, the frame rate and the encoding algorithm, and it sends RTP video packets;
the routers' behavior contribute to the loss rate or the loss distribution,
together with the traffic conditions in the network. The destination stores
the transmitted video sequence and collects the corresponding values of the
parameters. Then, by running the testbed or by using simulations, we produce and
store a set of distorted sequences along with the corresponding values of the
parameters.
After completing the ``Distorted Database'', a subjective quality test must be
carried out. There are several subjective quality methods in the recommendations
of the ITU-R or ITU-T depending on the type of media in
hands. Details on this step come in Section 4.3. In
general, a group of human subjects is invited to evaluate the quality of
the sequences (i.e. every subject gives each sequence a score from a predefined
quality scale). The subjects should not establish any relation between the
sequences and the corresponding parameters' values.
The next step is to calculate the MOS values for all the sequences. Based on the scores given by the human subjects, screening and statistical analysis may be carried out to remove the grading of the individuals suspected to give unreliable results [73]. See Section 4.4 for more details about this step. After that, we store the MOS values and the corresponding parameters' values in a second database (which we call the ``Quality Database'').
In the third step, a suitable NN architecture and a training algorithm should be selected. The Quality Database is divided into two parts: one to train the NN and the other one to test its accuracy. The trained NN will then be able to evaluate the quality measure for any given values of the parameters. More details about this part are given in Section 4.5.
To put this more formally, we build a set
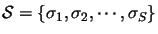 of media sequences that have encountered
varied conditions when transmitted and that constitute the ``training part'' of
the Quality Database. We also define a set
of media sequences that have encountered
varied conditions when transmitted and that constitute the ``training part'' of
the Quality Database. We also define a set
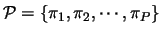 of parameters such as the bit rate of the source, the packet loss rate in the network, etc. Then, we denote by
of parameters such as the bit rate of the source, the packet loss rate in the network, etc. Then, we denote by 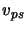 the value of parameter
the value of parameter 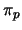 in sequence
in sequence 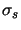 , and by
, and by 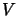 the matrix
the matrix 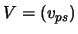 . For
. For
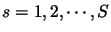 , sequence receives the MOS evaluation
, sequence receives the MOS evaluation
![$\mu_s \in [N,M]$](img276.gif) from the subjective test phase. The goal of the NN is to find a real function
from the subjective test phase. The goal of the NN is to find a real function 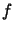 having
having 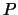 real variables and with values in
real variables and with values in ![$[N,M]$](img279.gif) , such that
, such that
- (i)
- for any sequence
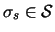 ,
,
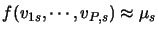 ,
,
- (ii)
- and such that for any other vector of parameter values
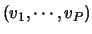 ,
,
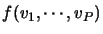 is close to the MOS that would receive any media sequence for which the selected parameters would have those specific values
is close to the MOS that would receive any media sequence for which the selected parameters would have those specific values
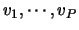 .
.
Once all the above steps are completed successfully, we implement the final tool, which is composed of two modules: the first one collects the values of the selected quality-affecting parameters (based on the network state, the codec parameters, etc.). These values are fed into the second one, which is the trained NN that will take the given values of the quality-affecting parameters and correspondingly computes instantaneously the MOS quality score.
All the above steps are summarized into the four parts shown in Figure 4.1. In the first part, we have to identify the quality-affecting parameters, their ranges and values, to choose the original sequences, and to produce the distorted database. In the second part, the subjective quality test is carried out for the distorted database and the MOS scores (together with their statistical analysis) are calculated in order to form the quality database. In the third part, we select the NN architecture and learning algorithm, and train and test it using the quality database. Finally, in the fourth step, we implement the final tool that consists of the two parts (parameters collection and MOS evaluation), in order to obtain a real-time quality evaluator. These steps are also shown in a block diagram in Figure 4.2.
Subsections
Next: More than one Media
Up: Descriptions of Our New
Previous: Introduction
Contents
Index
Samir Mohamed
2003-01-08